OpenACC: Parallelization and Optimization
Data movement is an important part to optimize when using GPUs
Keeping data on the GPU as long as possible
Getting the compiler to generate parallel code
Addressing loop performance optimization
Data access and execution divergence are important for GPU performance
The himeno benchmark
/*********************************************************************
This benchmark test program is measuring a cpu performance
of floating point operation and memory access speed.
Modification needed for testing turget computer!!
Please adjust parameter : nn to take one minute to execute
all calculation. Original parameter set is for PC with
200 MHz MMX PENTIUM, whose score using this benchmark test
is about 32.3 MFLOPS.
If you have any question, please ask me via email.
written by Ryutaro HIMENO, October 3, 1998.
Version 2.0
----------------------------------------------
Ryutaro Himeno, Dr. of Eng.
Head of Computer Information Center,
The Institute of Pysical and Chemical Research (RIKEN)
Email : himeno@postman.riken.go.jp
---------------------------------------------------------------
You can adjust the size of this benchmark code to fit your target
computer. In that case, please chose following sets of
(mimax,mjmax,mkmax):
small : 129,65,65
midium: 257,129,129
large : 513,257,257
ext.large: 1025,513,513
This program is to measure a computer performance in MFLOPS
by using a kernel which appears in a linear solver of pressure
Poisson included in an incompressible Navier-Stokes solver.
A point-Jacobi method is employed in this solver.
------------------
Finite-difference method, curvilinear coodinate system
Vectorizable and parallelizable on each grid point
No. of grid points : imax x jmax x kmax including boundaries
------------------
A,B,C:coefficient matrix, wrk1: source term of Poisson equation
wrk2 : working area, OMEGA : relaxation parameter
BND:control variable for boundaries and objects ( = 0 or 1)
P: pressure
-----------------
-------------------
"use portlib" statement on the next line is for Visual fortran
to use UNIX libraries. Please remove it if your system is UNIX.
-------------------
use portlib
Version 0.2
*********************************************************************/
#include <stdio.h>
#include "himeno_C.h"
#ifdef SMALL
#define MIMAX 129
#define MJMAX 65
#define MKMAX 65
#endif
#ifdef MIDDLE
#define MIMAX 257
#define MJMAX 129
#define MKMAX 129
#endif
#ifdef LARGE
#define MIMAX 513
#define MJMAX 257
#define MKMAX 257
#endif
#ifdef DOUBLE_PRECISION
typedef double real;
#else
typedef float real;
#endif
static real p[MIMAX][MJMAX][MKMAX];
static real a[MIMAX][MJMAX][MKMAX][4],
b[MIMAX][MJMAX][MKMAX][3],
c[MIMAX][MJMAX][MKMAX][3];
static real bnd[MIMAX][MJMAX][MKMAX];
static real wrk1[MIMAX][MJMAX][MKMAX],
wrk2[MIMAX][MJMAX][MKMAX];
#define NN 3
double second();
real jacobi(int);
void initmt();
static int imax, jmax, kmax;
static real omega;
int
main()
{
int i, j, k;
real gosa;
double cpu0, cpu1, nflop, xmflops2, score;
omega = 0.8;
imax = MIMAX-1;
jmax = MJMAX-1;
kmax = MKMAX-1;
/*
* Initializing matrixes
*/
initmt();
printf("mimax = %d mjmax = %d mkmax = %d\n",MIMAX, MJMAX, MKMAX);
printf("imax = %d jmax = %d kmax =%d\n",imax,jmax,kmax);
/*
* Start measuring
*/
cpu0 = second();
/*
* Jacobi iteration
*/
gosa = jacobi(NN);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)NN;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",NN);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
// Now estimate how many iterations could be done in 20s
int nn2 = 20.0/cpu1*NN;
cpu0 = second();
gosa = jacobi(nn2);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)nn2;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",nn2);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
return (0);
}
void initmt()
{
int i,j,k;
// TODO: Implement data initialization with OpenACC on device
// TODO: Implement computation with OpenACC on device
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=0.0;
a[i][j][k][1]=0.0;
a[i][j][k][2]=0.0;
a[i][j][k][3]=0.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=0.0;
c[i][j][k][1]=0.0;
c[i][j][k][2]=0.0;
p[i][j][k]=0.0;
wrk1[i][j][k]=0.0;
bnd[i][j][k]=0.0;
}
// TODO: Implement computation with OpenACC on device
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=1.0;
a[i][j][k][1]=1.0;
a[i][j][k][2]=1.0;
a[i][j][k][3]=1.0/6.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=1.0;
c[i][j][k][1]=1.0;
c[i][j][k][2]=1.0;
p[i][j][k]=(real)(k*k)/(real)((kmax-1)*(kmax-1));
wrk1[i][j][k]=0.0;
bnd[i][j][k]=1.0;
}
}
real jacobi(int nn)
{
int i,j,k,n;
real gosa, s0, ss;
// TODO: Implement data initialization with OpenACC on device
for(n=0;n<nn;++n){
gosa = 0.0;
// TODO: Implement computation with OpenACC on device
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
s0 = a[i][j][k][0] * p[i+1][j ][k ]
+ a[i][j][k][1] * p[i ][j+1][k ]
+ a[i][j][k][2] * p[i ][j ][k+1]
+ b[i][j][k][0] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
- p[i-1][j+1][k ] + p[i-1][j-1][k ] )
+ b[i][j][k][1] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
- p[i ][j+1][k-1] + p[i ][j-1][k-1] )
+ b[i][j][k][2] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
- p[i+1][j ][k-1] + p[i-1][j ][k-1] )
+ c[i][j][k][0] * p[i-1][j ][k ]
+ c[i][j][k][1] * p[i ][j-1][k ]
+ c[i][j][k][2] * p[i ][j ][k-1]
+ wrk1[i][j][k];
ss = ( s0 * a[i][j][k][3] - p[i][j][k] ) * bnd[i][j][k];
gosa = gosa + ss*ss;
wrk2[i][j][k] = p[i][j][k] + omega * ss;
}
printf("nn %d, gosa %f\n",n,gosa);
// TODO: Implement computation with OpenACC on device
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k)
p[i][j][k] = wrk2[i][j][k];
} /* end n loop */
return(gosa);
}
double second()
{
#include <sys/time.h>
struct timeval tm;
double t ;
static int base_sec = 0,base_usec = 0;
gettimeofday(&tm, NULL);
if(base_sec == 0 && base_usec == 0)
{
base_sec = tm.tv_sec;
base_usec = tm.tv_usec;
t = 0.0;
} else {
t = (double) (tm.tv_sec-base_sec) +
((double) (tm.tv_usec-base_usec))/1.0e6 ;
}
return t ;
}
/*********************************************************************
This benchmark test program is measuring a cpu performance
of floating point operation and memory access speed.
Modification needed for testing turget computer!!
Please adjust parameter : nn to take one minute to execute
all calculation. Original parameter set is for PC with
200 MHz MMX PENTIUM, whose score using this benchmark test
is about 32.3 MFLOPS.
If you have any question, please ask me via email.
written by Ryutaro HIMENO, October 3, 1998.
Version 2.0
----------------------------------------------
Ryutaro Himeno, Dr. of Eng.
Head of Computer Information Center,
The Institute of Pysical and Chemical Research (RIKEN)
Email : himeno@postman.riken.go.jp
---------------------------------------------------------------
You can adjust the size of this benchmark code to fit your target
computer. In that case, please chose following sets of
(mimax,mjmax,mkmax):
small : 129,65,65
midium: 257,129,129
large : 513,257,257
ext.large: 1025,513,513
This program is to measure a computer performance in MFLOPS
by using a kernel which appears in a linear solver of pressure
Poisson included in an incompressible Navier-Stokes solver.
A point-Jacobi method is employed in this solver.
------------------
Finite-difference method, curvilinear coodinate system
Vectorizable and parallelizable on each grid point
No. of grid points : imax x jmax x kmax including boundaries
------------------
A,B,C:coefficient matrix, wrk1: source term of Poisson equation
wrk2 : working area, OMEGA : relaxation parameter
BND:control variable for boundaries and objects ( = 0 or 1)
P: pressure
-----------------
-------------------
"use portlib" statement on the next line is for Visual fortran
to use UNIX libraries. Please remove it if your system is UNIX.
-------------------
use portlib
Version 0.2
*********************************************************************/
#include <stdio.h>
#include "himeno_C.h"
#ifdef SMALL
#define MIMAX 129
#define MJMAX 65
#define MKMAX 65
#endif
#ifdef MIDDLE
#define MIMAX 257
#define MJMAX 129
#define MKMAX 129
#endif
#ifdef LARGE
#define MIMAX 513
#define MJMAX 257
#define MKMAX 257
#endif
#ifdef DOUBLE_PRECISION
typedef double real;
#else
typedef float real;
#endif
static real p[MIMAX][MJMAX][MKMAX];
static real a[MIMAX][MJMAX][MKMAX][4],
b[MIMAX][MJMAX][MKMAX][3],
c[MIMAX][MJMAX][MKMAX][3];
static real bnd[MIMAX][MJMAX][MKMAX];
static real wrk1[MIMAX][MJMAX][MKMAX],
wrk2[MIMAX][MJMAX][MKMAX];
#define NN 3
double second();
real jacobi(int);
void initmt();
static int imax, jmax, kmax;
static real omega;
int
main()
{
int i, j, k;
real gosa;
double cpu0, cpu1, nflop, xmflops2, score;
omega = 0.8;
imax = MIMAX-1;
jmax = MJMAX-1;
kmax = MKMAX-1;
/*
* Initializing matrixes
*/
initmt();
printf("mimax = %d mjmax = %d mkmax = %d\n",MIMAX, MJMAX, MKMAX);
printf("imax = %d jmax = %d kmax =%d\n",imax,jmax,kmax);
/*
* Start measuring
*/
cpu0 = second();
/*
* Jacobi iteration
*/
gosa = jacobi(NN);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)NN;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",NN);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
// Now estimate how many iterations could be done in 20s
int nn2 = 20.0/cpu1*NN;
cpu0 = second();
gosa = jacobi(nn2);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)nn2;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",nn2);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
return (0);
}
void initmt()
{
int i,j,k;
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=0.0;
a[i][j][k][1]=0.0;
a[i][j][k][2]=0.0;
a[i][j][k][3]=0.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=0.0;
c[i][j][k][1]=0.0;
c[i][j][k][2]=0.0;
p[i][j][k]=0.0;
wrk1[i][j][k]=0.0;
bnd[i][j][k]=0.0;
}
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=1.0;
a[i][j][k][1]=1.0;
a[i][j][k][2]=1.0;
a[i][j][k][3]=1.0/6.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=1.0;
c[i][j][k][1]=1.0;
c[i][j][k][2]=1.0;
p[i][j][k]=(real)(k*k)/(real)((kmax-1)*(kmax-1));
wrk1[i][j][k]=0.0;
bnd[i][j][k]=1.0;
}
}
real jacobi(int nn)
{
int i,j,k,n;
real gosa, s0, ss;
for(n=0;n<nn;++n){
gosa = 0.0;
#pragma acc parallel loop private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
s0 = a[i][j][k][0] * p[i+1][j ][k ]
+ a[i][j][k][1] * p[i ][j+1][k ]
+ a[i][j][k][2] * p[i ][j ][k+1]
+ b[i][j][k][0] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
- p[i-1][j+1][k ] + p[i-1][j-1][k ] )
+ b[i][j][k][1] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
- p[i ][j+1][k-1] + p[i ][j-1][k-1] )
+ b[i][j][k][2] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
- p[i+1][j ][k-1] + p[i-1][j ][k-1] )
+ c[i][j][k][0] * p[i-1][j ][k ]
+ c[i][j][k][1] * p[i ][j-1][k ]
+ c[i][j][k][2] * p[i ][j ][k-1]
+ wrk1[i][j][k];
ss = ( s0 * a[i][j][k][3] - p[i][j][k] ) * bnd[i][j][k];
gosa = gosa + ss*ss;
wrk2[i][j][k] = p[i][j][k] + omega * ss;
}
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k)
p[i][j][k] = wrk2[i][j][k];
} /* end n loop */
return(gosa);
}
double second()
{
#include <sys/time.h>
struct timeval tm;
double t ;
static int base_sec = 0,base_usec = 0;
gettimeofday(&tm, NULL);
if(base_sec == 0 && base_usec == 0)
{
base_sec = tm.tv_sec;
base_usec = tm.tv_usec;
t = 0.0;
} else {
t = (double) (tm.tv_sec-base_sec) +
((double) (tm.tv_usec-base_usec))/1.0e6 ;
}
return t ;
}
/*********************************************************************
This benchmark test program is measuring a cpu performance
of floating point operation and memory access speed.
Modification needed for testing turget computer!!
Please adjust parameter : nn to take one minute to execute
all calculation. Original parameter set is for PC with
200 MHz MMX PENTIUM, whose score using this benchmark test
is about 32.3 MFLOPS.
If you have any question, please ask me via email.
written by Ryutaro HIMENO, October 3, 1998.
Version 2.0
----------------------------------------------
Ryutaro Himeno, Dr. of Eng.
Head of Computer Information Center,
The Institute of Pysical and Chemical Research (RIKEN)
Email : himeno@postman.riken.go.jp
---------------------------------------------------------------
You can adjust the size of this benchmark code to fit your target
computer. In that case, please chose following sets of
(mimax,mjmax,mkmax):
small : 129,65,65
midium: 257,129,129
large : 513,257,257
ext.large: 1025,513,513
This program is to measure a computer performance in MFLOPS
by using a kernel which appears in a linear solver of pressure
Poisson included in an incompressible Navier-Stokes solver.
A point-Jacobi method is employed in this solver.
------------------
Finite-difference method, curvilinear coodinate system
Vectorizable and parallelizable on each grid point
No. of grid points : imax x jmax x kmax including boundaries
------------------
A,B,C:coefficient matrix, wrk1: source term of Poisson equation
wrk2 : working area, OMEGA : relaxation parameter
BND:control variable for boundaries and objects ( = 0 or 1)
P: pressure
-----------------
-------------------
"use portlib" statement on the next line is for Visual fortran
to use UNIX libraries. Please remove it if your system is UNIX.
-------------------
use portlib
Version 0.2
*********************************************************************/
#include <stdio.h>
#include "himeno_C.h"
#ifdef SMALL
#define MIMAX 129
#define MJMAX 65
#define MKMAX 65
#endif
#ifdef MIDDLE
#define MIMAX 257
#define MJMAX 129
#define MKMAX 129
#endif
#ifdef LARGE
#define MIMAX 513
#define MJMAX 257
#define MKMAX 257
#endif
#ifdef DOUBLE_PRECISION
typedef double real;
#else
typedef float real;
#endif
static real p[MIMAX][MJMAX][MKMAX];
static real a[MIMAX][MJMAX][MKMAX][4],
b[MIMAX][MJMAX][MKMAX][3],
c[MIMAX][MJMAX][MKMAX][3];
static real bnd[MIMAX][MJMAX][MKMAX];
static real wrk1[MIMAX][MJMAX][MKMAX],
wrk2[MIMAX][MJMAX][MKMAX];
#define NN 3
double second();
real jacobi(int);
void initmt();
static int imax, jmax, kmax;
static real omega;
int
main()
{
int i, j, k;
real gosa;
double cpu0, cpu1, nflop, xmflops2, score;
omega = 0.8;
imax = MIMAX-1;
jmax = MJMAX-1;
kmax = MKMAX-1;
/*
* Initializing matrixes
*/
initmt();
printf("mimax = %d mjmax = %d mkmax = %d\n",MIMAX, MJMAX, MKMAX);
printf("imax = %d jmax = %d kmax =%d\n",imax,jmax,kmax);
/*
* Start measuring
*/
cpu0 = second();
/*
* Jacobi iteration
*/
gosa = jacobi(NN);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)NN;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",NN);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
// Now estimate how many iterations could be done in 20s
int nn2 = 20.0/cpu1*NN;
cpu0 = second();
gosa = jacobi(nn2);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)nn2;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",nn2);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
return (0);
}
void initmt()
{
int i,j,k;
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=0.0;
a[i][j][k][1]=0.0;
a[i][j][k][2]=0.0;
a[i][j][k][3]=0.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=0.0;
c[i][j][k][1]=0.0;
c[i][j][k][2]=0.0;
p[i][j][k]=0.0;
wrk1[i][j][k]=0.0;
bnd[i][j][k]=0.0;
}
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=1.0;
a[i][j][k][1]=1.0;
a[i][j][k][2]=1.0;
a[i][j][k][3]=1.0/6.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=1.0;
c[i][j][k][1]=1.0;
c[i][j][k][2]=1.0;
p[i][j][k]=(real)(k*k)/(real)((kmax-1)*(kmax-1));
wrk1[i][j][k]=0.0;
bnd[i][j][k]=1.0;
}
}
real jacobi(int nn)
{
int i,j,k,n;
real gosa, s0, ss;
#pragma acc data copyin(a,b,c,bnd,wrk1) copy(p) create(wrk2)
{
for(n=0;n<nn;++n){
gosa = 0.0;
#pragma acc parallel loop private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
s0 = a[i][j][k][0] * p[i+1][j ][k ]
+ a[i][j][k][1] * p[i ][j+1][k ]
+ a[i][j][k][2] * p[i ][j ][k+1]
+ b[i][j][k][0] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
- p[i-1][j+1][k ] + p[i-1][j-1][k ] )
+ b[i][j][k][1] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
- p[i ][j+1][k-1] + p[i ][j-1][k-1] )
+ b[i][j][k][2] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
- p[i+1][j ][k-1] + p[i-1][j ][k-1] )
+ c[i][j][k][0] * p[i-1][j ][k ]
+ c[i][j][k][1] * p[i ][j-1][k ]
+ c[i][j][k][2] * p[i ][j ][k-1]
+ wrk1[i][j][k];
ss = ( s0 * a[i][j][k][3] - p[i][j][k] ) * bnd[i][j][k];
gosa = gosa + ss*ss;
wrk2[i][j][k] = p[i][j][k] + omega * ss;
}
#pragma acc parallel loop
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k)
p[i][j][k] = wrk2[i][j][k];
} /* end n loop */
} /* end acc data region */
return(gosa);
}
double second()
{
#include <sys/time.h>
struct timeval tm;
double t ;
static int base_sec = 0,base_usec = 0;
gettimeofday(&tm, NULL);
if(base_sec == 0 && base_usec == 0)
{
base_sec = tm.tv_sec;
base_usec = tm.tv_usec;
t = 0.0;
} else {
t = (double) (tm.tv_sec-base_sec) +
((double) (tm.tv_usec-base_usec))/1.0e6 ;
}
return t ;
}
/*********************************************************************
This benchmark test program is measuring a cpu performance
of floating point operation and memory access speed.
Modification needed for testing turget computer!!
Please adjust parameter : nn to take one minute to execute
all calculation. Original parameter set is for PC with
200 MHz MMX PENTIUM, whose score using this benchmark test
is about 32.3 MFLOPS.
If you have any question, please ask me via email.
written by Ryutaro HIMENO, October 3, 1998.
Version 2.0
----------------------------------------------
Ryutaro Himeno, Dr. of Eng.
Head of Computer Information Center,
The Institute of Pysical and Chemical Research (RIKEN)
Email : himeno@postman.riken.go.jp
---------------------------------------------------------------
You can adjust the size of this benchmark code to fit your target
computer. In that case, please chose following sets of
(mimax,mjmax,mkmax):
small : 129,65,65
midium: 257,129,129
large : 513,257,257
ext.large: 1025,513,513
This program is to measure a computer performance in MFLOPS
by using a kernel which appears in a linear solver of pressure
Poisson included in an incompressible Navier-Stokes solver.
A point-Jacobi method is employed in this solver.
------------------
Finite-difference method, curvilinear coodinate system
Vectorizable and parallelizable on each grid point
No. of grid points : imax x jmax x kmax including boundaries
------------------
A,B,C:coefficient matrix, wrk1: source term of Poisson equation
wrk2 : working area, OMEGA : relaxation parameter
BND:control variable for boundaries and objects ( = 0 or 1)
P: pressure
-----------------
-------------------
"use portlib" statement on the next line is for Visual fortran
to use UNIX libraries. Please remove it if your system is UNIX.
-------------------
use portlib
Version 0.2
*********************************************************************/
#include <stdio.h>
#include "himeno_C.h"
#ifdef SMALL
#define MIMAX 129
#define MJMAX 65
#define MKMAX 65
#endif
#ifdef MIDDLE
#define MIMAX 257
#define MJMAX 129
#define MKMAX 129
#endif
#ifdef LARGE
#define MIMAX 513
#define MJMAX 257
#define MKMAX 257
#endif
#ifdef DOUBLE_PRECISION
typedef double real;
#else
typedef float real;
#endif
static real p[MIMAX][MJMAX][MKMAX];
static real a[MIMAX][MJMAX][MKMAX][4],
b[MIMAX][MJMAX][MKMAX][3],
c[MIMAX][MJMAX][MKMAX][3];
static real bnd[MIMAX][MJMAX][MKMAX];
static real wrk1[MIMAX][MJMAX][MKMAX],
wrk2[MIMAX][MJMAX][MKMAX];
#define NN 3
double second();
real jacobi(int);
void initmt();
static int imax, jmax, kmax;
static real omega;
int
main()
{
int i, j, k;
real gosa;
double cpu0, cpu1, nflop, xmflops2, score;
omega = 0.8;
imax = MIMAX-1;
jmax = MJMAX-1;
kmax = MKMAX-1;
#pragma acc data create(a,b,c,p,wrk1,bnd,wrk2)
{
/*
* Initializing matrixes
*/
initmt();
printf("mimax = %d mjmax = %d mkmax = %d\n",MIMAX, MJMAX, MKMAX);
printf("imax = %d jmax = %d kmax =%d\n",imax,jmax,kmax);
/*
* Start measuring
*/
cpu0 = second();
/*
* Jacobi iteration
*/
gosa = jacobi(NN);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)NN;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",NN);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
// Now estimate how many iterations could be done in 20s
int nn2 = 20.0/cpu1*NN;
cpu0 = second();
gosa = jacobi(nn2);
cpu1 = second();
cpu1 = cpu1 - cpu0;
nflop = (kmax-2)*(jmax-2)*(imax-2)*34;
if(cpu1 != 0.0)
xmflops2 = nflop/cpu1*1.0e-6*(real)nn2;
score = xmflops2/32.27;
printf("\ncpu : %f sec.\n", cpu1);
printf("Loop executed for %d times\n",nn2);
printf("Gosa : %e \n",gosa);
printf("MFLOPS measured : %f\n",xmflops2);
printf("Score based on MMX Pentium 200MHz : %f\n",score);
} /* end acc data region */
return (0);
}
void initmt()
{
int i,j,k;
#pragma acc data present(a,b,c,p,wrk1,bnd)
{
#pragma acc parallel loop collapse(3)
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=0.0;
a[i][j][k][1]=0.0;
a[i][j][k][2]=0.0;
a[i][j][k][3]=0.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=0.0;
c[i][j][k][1]=0.0;
c[i][j][k][2]=0.0;
p[i][j][k]=0.0;
wrk1[i][j][k]=0.0;
bnd[i][j][k]=0.0;
}
#pragma acc parallel loop collapse(3)
for(i=0 ; i<imax ; ++i)
for(j=0 ; j<jmax ; ++j)
for(k=0 ; k<kmax ; ++k){
a[i][j][k][0]=1.0;
a[i][j][k][1]=1.0;
a[i][j][k][2]=1.0;
a[i][j][k][3]=1.0/6.0;
b[i][j][k][0]=0.0;
b[i][j][k][1]=0.0;
b[i][j][k][2]=0.0;
c[i][j][k][0]=1.0;
c[i][j][k][1]=1.0;
c[i][j][k][2]=1.0;
p[i][j][k]=(real)(k*k)/(real)((kmax-1)*(kmax-1));
wrk1[i][j][k]=0.0;
bnd[i][j][k]=1.0;
}
} /* end acc data region */
}
real jacobi(int nn)
{
int i,j,k,n;
real gosa, s0, ss;
#pragma acc data present(a,b,c,bnd,wrk1,p,wrk2)
{
for(n=0;n<nn;++n){
gosa = 0.0;
#pragma acc parallel loop collapse(3) private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
s0 = a[i][j][k][0] * p[i+1][j ][k ]
+ a[i][j][k][1] * p[i ][j+1][k ]
+ a[i][j][k][2] * p[i ][j ][k+1]
+ b[i][j][k][0] * ( p[i+1][j+1][k ] - p[i+1][j-1][k ]
- p[i-1][j+1][k ] + p[i-1][j-1][k ] )
+ b[i][j][k][1] * ( p[i ][j+1][k+1] - p[i ][j-1][k+1]
- p[i ][j+1][k-1] + p[i ][j-1][k-1] )
+ b[i][j][k][2] * ( p[i+1][j ][k+1] - p[i-1][j ][k+1]
- p[i+1][j ][k-1] + p[i-1][j ][k-1] )
+ c[i][j][k][0] * p[i-1][j ][k ]
+ c[i][j][k][1] * p[i ][j-1][k ]
+ c[i][j][k][2] * p[i ][j ][k-1]
+ wrk1[i][j][k];
ss = ( s0 * a[i][j][k][3] - p[i][j][k] ) * bnd[i][j][k];
gosa = gosa + ss*ss;
wrk2[i][j][k] = p[i][j][k] + omega * ss;
}
#pragma acc parallel loop collapse(3)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k)
p[i][j][k] = wrk2[i][j][k];
} /* end n loop */
} /* end acc data region */
return(gosa);
}
double second()
{
#include <sys/time.h>
struct timeval tm;
double t ;
static int base_sec = 0,base_usec = 0;
gettimeofday(&tm, NULL);
if(base_sec == 0 && base_usec == 0)
{
base_sec = tm.tv_sec;
base_usec = tm.tv_usec;
t = 0.0;
} else {
t = (double) (tm.tv_sec-base_sec) +
((double) (tm.tv_usec-base_usec))/1.0e6 ;
}
return t ;
}
Optimizing data movement
Constructs and clauses for
defining the variables on the device
transferring data to/from the device
All variables used inside the
parallelorkernelsregion will be treated as implicit variables if they are not present in any data clauses, i.e. copying to and from to the device is automatically performedMinimize the data transfer between host and device
for(n=0;n<nn;++n){
gosa = 0.0;
#pragma acc parallel loop private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
(refer to examples/himeno_C_v01.c)
$ export PGI_ACC_TIME=1
$ cp himeno_C_v01.c himeno_C.c && make
...
215, Generating implicit copyout(wrk2[1:imax-2][1:jmax-2][1:kmax-2]) [if not already present]
Generating implicit copyin(wrk1[1:imax-2][1:jmax-2][1:kmax-2]) [if not already present]
Generating implicit copy(gosa) [if not already present]
Generating implicit copyin(b[1:imax-2][1:jmax-2][1:kmax-2][:],a[1:imax-2][1:jmax-2][1:kmax-2][:],bnd[1:imax-2][1:jmax-2][1:kmax-2],p[:imax][:jmax][:kmax],c[1:imax-2][1:jmax-2][1:kmax-2][:]) [if not already present]
$ sbatch run_himeno.sh
jacobi NVIDIA devicenum=0
time(us): 26,955,638
215: compute region reached 4 times
215: kernel launched 4 times
grid: [510] block: [128]
elapsed time(us): total=15,708 max=4,019 min=3,894 avg=3,927
215: reduction kernel launched 4 times
grid: [1] block: [256]
elapsed time(us): total=85 max=29 min=18 avg=21
215: data region reached 8 times
215: data copyin transfers: 3115092
device time(us): total=20,563,324 max=28,863 min=5 avg=6
237: data copyout transfers: 518164
device time(us): total=6,392,314 max=27,802 min=11 avg=12
#pragma acc data copyin(a,b,c,bnd,wrk1) copy(p) create(wrk2)
{
for(n=0;n<nn;++n){
gosa = 0.0;
#pragma acc parallel loop private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
(refer to examples/himeno_C_v02.c)
$ export PGI_ACC_TIME=1
$ cp himeno_C_v02.c himeno_C.c && make
$ sbatch run_himeno.sh
jacobi NVIDIA devicenum=0
time(us): 384,219
212: data region reached 4 times
212: data copyin transfers: 220
device time(us): total=308,182 max=1,483 min=121 avg=1,400
247: data copyout transfers: 18
device time(us): total=74,577 max=4,861 min=327 avg=4,143
217: compute region reached 83 times
217: kernel launched 83 times
grid: [510] block: [128]
elapsed time(us): total=345,316 max=28,382 min=3,813 avg=4,160
217: reduction kernel launched 83 times
grid: [1] block: [256]
elapsed time(us): total=1,473 max=38 min=16 avg=17
217: data region reached 166 times
217: data copyin transfers: 83
device time(us): total=431 max=13 min=5 avg=5
239: data copyout transfers: 83
device time(us): total=1,029 max=24 min=11 avg=12
242: compute region reached 83 times
242: kernel launched 83 times
grid: [510] block: [128]
elapsed time(us): total=71,775 max=885 min=852 avg=864
Optimize Loop performance
The compiler is usually pretty good at choosing how to break up loop iterations to run well on parallel accelerators.
Sometimes we can obtain more performance by guiding the compiler to make specific choices.
Collapse Clause
collapse(N)
Same as in OpenMP, take the next N tightly nested loops and flatten them into a one loop
Can be beneficial when loops are small
Breaks the next loops into tiles (blocks) before parallelizing the loops
For certain memory access patterns this can improve data locality
#pragma acc parallel loop collapse(3) private(i,j,k,s0,ss) reduction(+:gosa)
for(i=1 ; i<imax-1 ; ++i)
for(j=1 ; j<jmax-1 ; ++j)
for(k=1 ; k<kmax-1 ; ++k){
(refer to examples/himeno_C_v03.c)
$ export PGI_ACC_TIME=1
$ cp himeno_C_v03.c himeno_C.c && make
$ sbatch run_himeno.sh
jacobi NVIDIA devicenum=0
time(us): 22,300
221: data region reached 4 times
226: compute region reached 1322 times
226: kernel launched 1322 times
grid: [65535] block: [128]
elapsed time(us): total=4,012,812 max=30,035 min=2,960 avg=3,035
226: reduction kernel launched 1322 times
grid: [1] block: [256]
elapsed time(us): total=128,708 max=138 min=95 avg=97
226: data region reached 2644 times
226: data copyin transfers: 1322
device time(us): total=6,627 max=10 min=5 avg=5
248: data copyout transfers: 1322
device time(us): total=15,673 max=94 min=10 avg=11
251: compute region reached 1322 times
251: kernel launched 1322 times
grid: [65535] block: [128]
Loop directives
Loop directive accepts several fine-tuning clauses, OpenACC has three levels of parallelism
gang– have one or more workers that share resources, such as streaming multiprocessor - Multiple gangs work independently
worker– compute a vector
vector– threads work in SIMT (SIMD) fashion
seq– run sequentially
Multiple levels can be applied to a loop nest, but they have to be applied in top-down order
By default, when programming for a GPU, gang and vector parallelism is automatically applied.
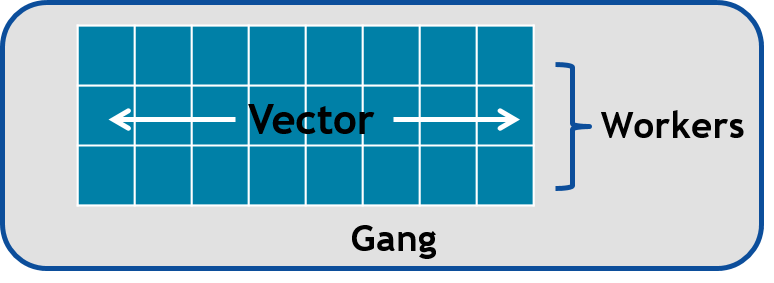
This image represents a single gang. When parallelizing our for loops, the loop iterations will be broken up evenly among a number of gangs. Each gang will contain a number of threads. These threads are organized into blocks. A worker is a row of threads. In the above graphic, there are 3 workers, which means that there are 3 rows of threads. The vector refers to how long each row is. So in the above graphic, the vector is 8, because each row is 8 threads long.
#pragma acc parallel num_gangs( 2 ) num_workers( 4 ) vector_length( 32 )
{
#pragma acc loop gang worker
for(int i = 0; i < N; i++)
{
#pragma acc loop vector
for(int j = 0; j < M; j++)
{
< loop code >
}
}
}
Avoid wasting Threads, when parallelizing small arrays, you have to be careful that the number of threads within your vector is not larger than the number of loop iterations.
#pragma acc kernels loop gang
for(int i = 0; i < 1000000000; i++)
{
#pragma acc loop vector(256)
for(int j = 0; j < 32; j++)
{
< loop code >
}
}
The Rule of 32 (Warps): The general rule of thumb for programming for NVIDIA GPUs is to always ensure that your vector length is a multiple of 32 (which means 32, 64, 96, 128, … 512, … 1024… etc.). This is because NVIDIA GPUs are optimized to use warps. Warps are groups of 32 threads that are executing the same computer instruction.
What values should I try?
Depends on the accelerator you are using
You can try out different combinations, but deterministic optimizations require good knowledge on the accelerator hardware
In the case of NVIDIA GPUs you should start with the NVVP results and refer to CUDA documentation
One hard-coded value: for NVIDIA GPUs the vector length should always be 32, which is the (current) warp size
Device data interoperability
OpenACC includes methods to access to device data pointers
Device data pointers can be used to interoperate with libraries and other programming techniques available for accelerator devices
CUDA kernels and libraries
CUDA-aware MPI libraries
Calling CUDA-kernel from OpenACC-program
Define a device address to be available on the host
C/C++:
#pragma acc host_data [clause]Fortran:
!$acc host_data [clause]
Only a single clause is allowed: C/C++, Fortran:
use_device(var-list)Within the construct, all the variables in var-list are referred to by using their device addresses
#pragma acc data present(u[0:n1*n2*n3],v[0:n1*n2*n3],a[0:4],r[0:n1*n2*n3])
{
#pragma acc host_data use_device(u,v,r,a)
{
resid_cuda(u,v,r,&n1,&n2,&n3,a);
}
}
extern "C" void resid_cuda(double *u, double *v, double *r,
int *n1, int *n2, int *n3,
double *a)
Summary
Data and Loop optimizations