
TensorFlow on a single GPU
TensorFlow is a well-known library developed primarily in Google which has been proven to be one of the most robust, reliable, and fast libraries for deep learning among developers. I think most of us have had some form of exposure to TensorFlow at some point in our deep learning/machine learning journey.
In this section we focus on using a single GPU for training our model. It is rather easy to transfer/port training of the model to the GPU with minimal coding.
TensorFlow supports running computations on a variety of types of devices, including CPU and GPU. They are represented with string identifiers for example:
/device:CPU:0: The CPU of your machine.
/GPU:0: Short-hand notation for the first GPU of your machine that is visible to TensorFlow.
/job:localhost/replica:0/task:0/device:GPU:1: Fully qualified name of the second GPU of your machine that is visible to TensorFlow.
If a TensorFlow operation has both CPU and GPU implementations, by default,
the GPU device is prioritized when the operation is assigned. For example, tf.matmul
has both CPU and GPU kernels and on a system with devices CPU:0 and GPU:0,
the GPU:0 device is selected to run tf.matmul unless you explicitly request
to run it on another device.
If a TensorFlow operation has no corresponding GPU implementation, then the operation
falls back to the CPU device. For example, since tf.cast only has a CPU kernel,
on a system with devices CPU:0 and GPU:0, the CPU:0 device is selected
to run tf.cast, even if requested to run on the GPU:0 device.
Get the physical devices
After booking a node with multiple GPUs, let’s check if we have TensorFlow module loaded and if the physical GPU device is available.
import tensorflow as tf
print("Num of GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
print("TensorFlow version: ", tf.__version__)
Num of GPUs Available: 6
TensorFlow version: 2.5.0
We can see the list of all of available devices:
tf.config.list_physical_devices()
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'),
PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:1', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:2', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:3', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:4', device_type='GPU'),
PhysicalDevice(name='/physical_device:GPU:5', device_type='GPU')]
If you have GPUs, then you should see the GPU device in the above list. We can also check specifically for the GPU or CPU devices.
tf.config.list_physical_devices('GPU')
tf.config.list_physical_devices('CPU')
Placement of calculations
TensorFlow automatically place tensor operations to physical devices which is by default is the GPU if available. Now, let’s define a random Tensor, and check where it is placed.
x = tf.random.uniform([3, 3])
x.device
'/job:localhost/replica:0/task:0/device:GPU:0'
The above string will end with GPU:K if the Tensor is placed on the K-th GPU device.
We can also check if a tensor is placed on a specific device by using device_endswith:
print("Is the Tensor on CPU #0: "),
print(x.device.endswith('CPU:0'))
print('')
print("Is the Tensor on GPU #0: "),
print(x.device.endswith('GPU:0'))
Is the Tensor on CPU #0:
False
Is the Tensor on GPU #0:
True
Determining the Placement
It is possible to force placement on specific devices, if they are available. We can view the benefits of GPU acceleration by running some tests and placing the operations on the CPU or GPU respectively.
import time
def time_matadd(x):
start = time.time()
for loop in range(10):
tf.add(x, x)
result = time.time()-start
print("Matrix addition (10 loops): {:0.2f}ms".format(1000*result))
def time_matmul(x):
start = time.time()
for loop in range(10):
tf.matmul(x, x)
result = time.time()-start
print("Matrix multiplication (10 loops): {:0.2f}ms".format(1000*result))
We run the above tests first on a CPU using tf.device("CPU:0"),
which forces the operations to be run on the CPU.
print("On CPU:")
with tf.device("CPU:0"):
x = tf.random.uniform([1000, 1000])
assert x.device.endswith("CPU:0")
time_matadd(x)
time_matmul(x)
On CPU:
Matrix addition (10 loops): 3.51ms
Matrix multiplication (10 loops): 199.40ms
And doing the same operations on the GPU:
if tf.config.experimental.list_physical_devices("GPU"):
print("On GPU:")
with tf.device("GPU:0"):
x = tf.random.uniform([1000, 1000])
assert x.device.endswith("GPU:0")
time_matadd(x)
time_matmul(x)
On GPU:
Matrix addition (10 loops): 0.89ms
Matrix multiplication (10 loops): 22.64ms
Note the significant time difference between running these operations on different devices.
Logging device placement
We can find out which devices your operations and tensors are assigned to by putting
tf.debugging.set_log_device_placement(True) as the first statement of your program.
Enabling device placement logging causes any Tensor allocations or operations to be printed.
The NLP model and the Quora dataset
The Quora Insincere Questions Classification dataset is consistent of a large set of question which were asked on Quora platform with a label to identify whether the question is sincere or insincere. An insincere question is defined as a question intended to make a statement rather than look for helpful answers, i.e. toxic content. The dataset can be downloaded from this link.
Our task is to use a language model to classify these questions. We need to tokenize questions and calculate the word embeddings using an NLP model afterwards. The output vector then can be attached to a classification head that can be trained on the dataset.
We have to possibilities to get the embeddings. We can either use
word-based representations or
context-based representations.
In a word-based representation of a question, the embeddings for each word (token) is calculated and the result will be the combined of all the embeddings, averaged over the question length.
Examples of pre-trained embeddings include:
Word2Vec: These are pre-trained embeddings of words learned from a large text corpora. Word2Vec has been pre-trained on a corpus of news articles with 300 million tokens, resulting in 300-dimensional vectors.
GloVe: has been pre-trained on a corpus of tweets with 27 billion tokens, resulting in 200-dimensional vectors.
In a Context-based representations, instead of learning vectors for each word in the sentence, a vector for a sentence on the whole, by taking into account the order of words and the set of co-occurring words, is computed
Examples of deep contextualized vectors include:
Embeddings from Language Models (ELMo): uses character-based word representations and bidirectional LSTMs. The pre-trained model computes a contextualized vector of 1024 dimensions. ELMo is available on Tensorflow Hub.
Universal Sentence Encoder (USE): The encoder uses a Transformer architecture that uses attention mechanism to incorporate information about the order and the collection of words. The pre-trained model of USE that returns a vector of 512 dimensions is also available on Tensorflow Hub.
Neural-Net Language Model (NNLM): The model simultaneously learns representations of words and probability functions for word sequences, allowing it to capture semantics of a sentence.
We will use a pretrained NNLM model available on Tensorflow Hub, that are trained on the English Google News 200B corpus, and computes a vector of 128 dimensions.
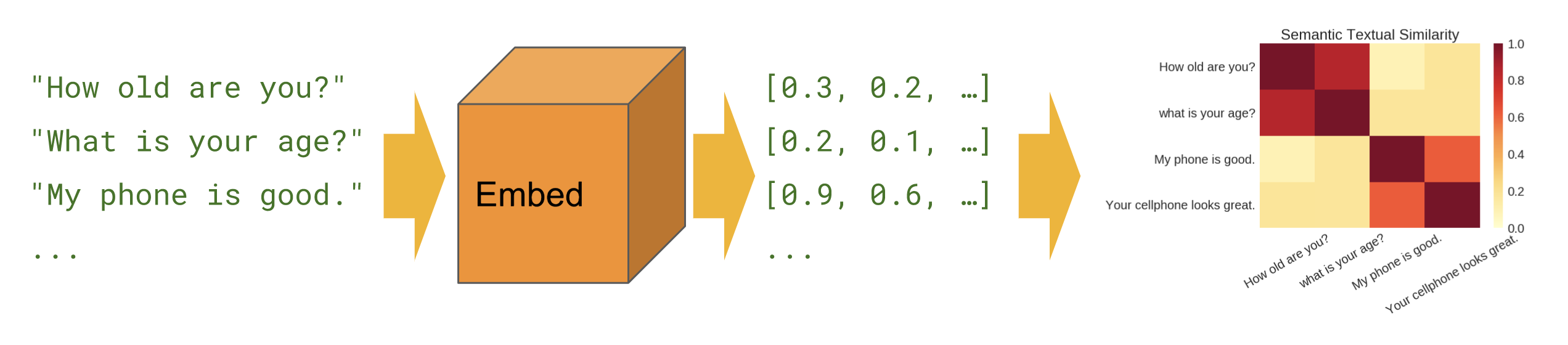
The figure above can help us to better understand of how embeddings calculated using context-based representation can be achieved. Semantic similarity is a measure of the degree to which two pieces of text carry the same meaning. This is broadly useful in obtaining good coverage over the numerous ways that a thought can be expressed using language without needing to manually enumerate them.

Training on CPU and GPU
You can find two neural networks for image classifier for the NNLM Language Model in
the github Transfer_Learning_NLP notebook.
Try to train the model on CPU and GPU. Compare the results.
Can you place manually some parts on GPU and some on CPU?