Introduction to GPU
Moore’s law
The number of transistors in a dense integrated circuit doubles about every two years. More transistors means smaller size of a single element, so higher core frequency can be achieved. However, power consumption scales as frequency in third power, so the growth in the core frequency has slowed down significantly. Higher performance of a single node has to rely on its more complicated structure and still can be achieved with SIMD, branch prediction, etc.
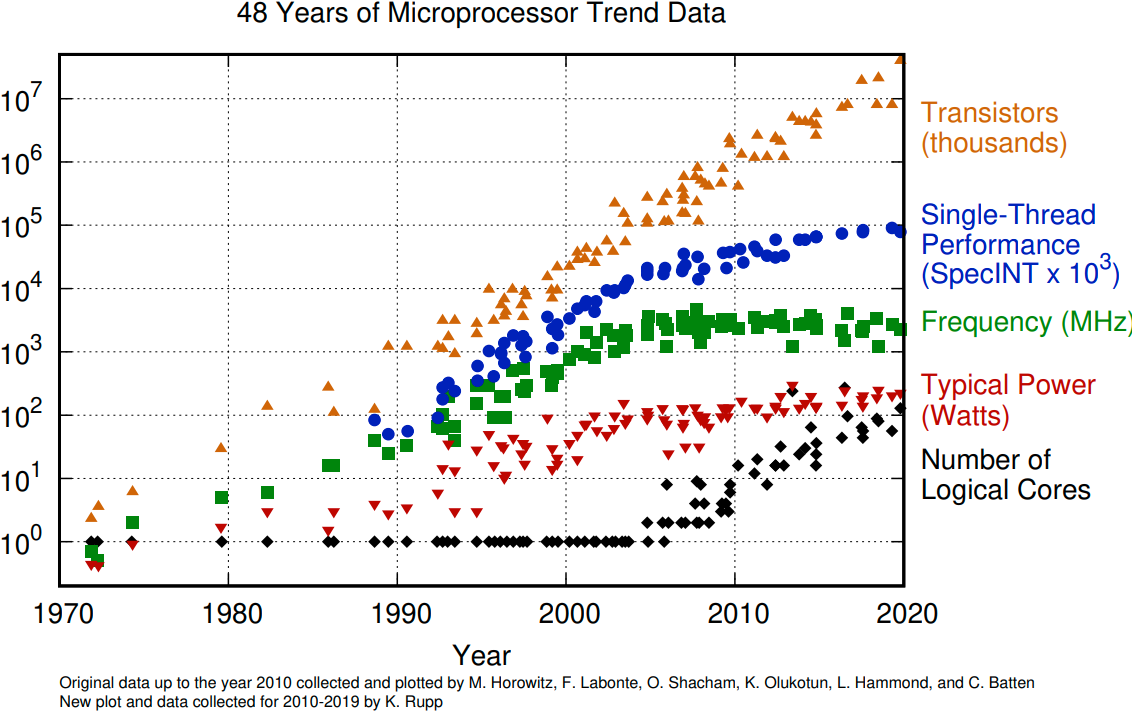
The evolution of microprocessors. The number of transistors per chip increase every 2 years or so. However it can no longer be explored by the core frequency due to power consumption limits. Before 2000, the increase in the single core clock frequency was the major source of the increase in the performance. Mid 2000 mark a transition towards multi-core processors.
Achieving performance has been based on two main strategies over the years:
Increase the single processor performance:
More recently, increase the number of physical cores.
Graphics processing units
The Graphics processing units (GPU) have been the most common accelerators during the last few years, the term GPU sometimes is used interchangeably with the term accelerator. GPUs were initially developed for highly-parallel task of graphic processing. Over the years, were used more and more in HPC. GPUs are a specialized parallel hardware for floating point operations. GPUs are co-processors for traditional CPUs: CPU still controls the work flow, delegating highly-parallel tasks to the GPU. Based on highly parallel architectures, which allows to take advantage of the increasing number of transistors.
Using GPUs allows one to achieve very high performance per node. As a result, the single GPU-equipped workstation can outperform small CPU-based cluster for some type of computational tasks. The drawback is: usually major rewrites of programs is required.
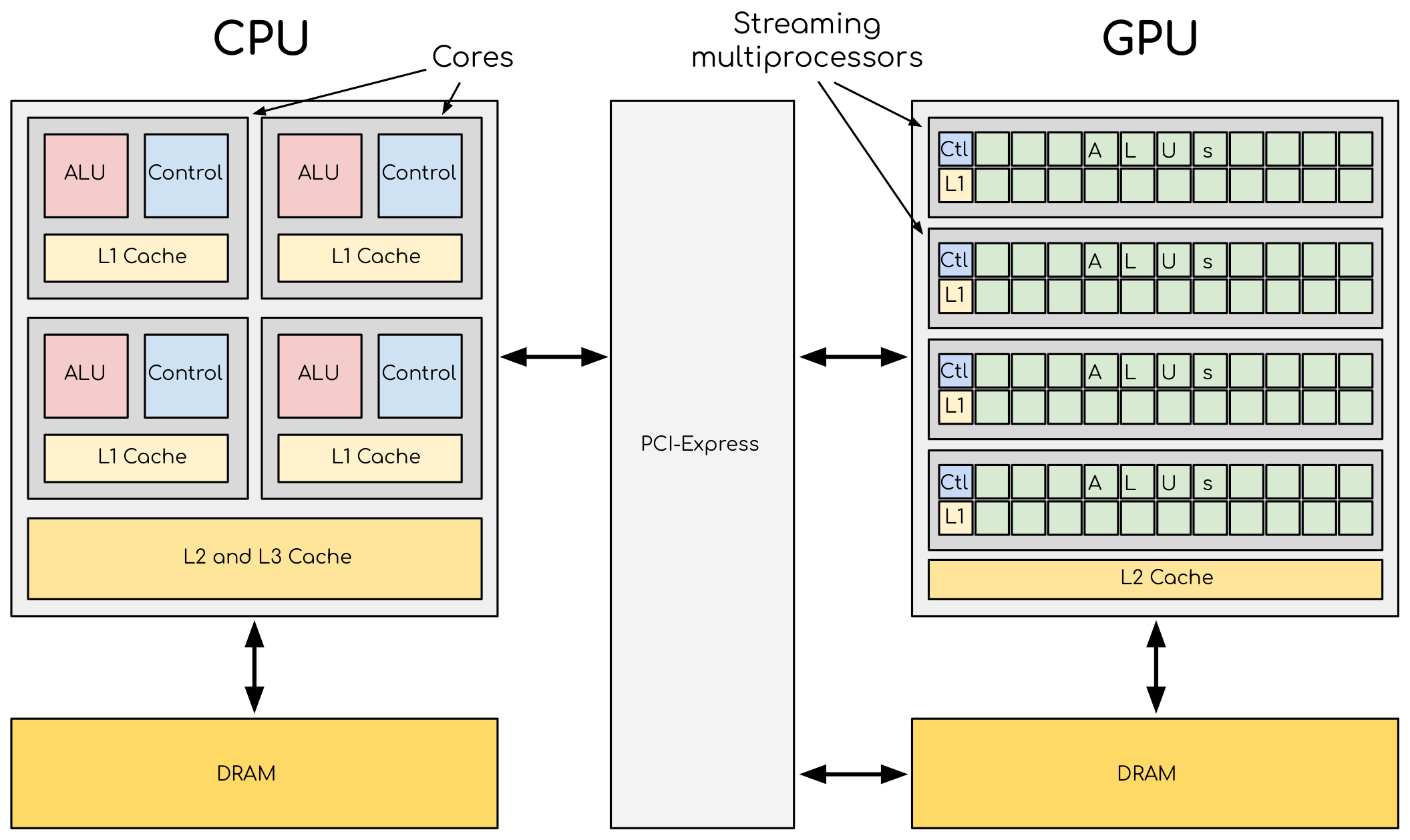
A comparison of the CPU and GPU architecture. CPU (left) has complex core structure and pack several cores on a single chip. GPU cores are very simple in comparison, they also share data and control between each other. This allows to pack more cores on a single chip, thus achieving very high compute density.
One of the most important features that allows the accelerators to reach this high performance is their scalability. Computational cores on accelerators are usually grouped into multiprocessors. The multiprocessors share the data and logical elements. This alows to achieve a very high density of a compute elements on a GPU. This also allows for better scaling: more multiprocessors means more raw performance and this is very easy to achieve with more transistors available.
Accelerators are a separate main circuit board with the processor, memory, power management, etc. It is connected to the motherboard with CPUs via PCIe bus. Having its own memory means that the data has to be copied to and from it. CPU acts as a main processor, controlling the execution workflow. It copies the data from its own memory to the GPU memory, executes the program and copies the results back. GPUs runs tens of thousands of threads simultaneously on thousands of cores and does not do much of the data management. With many cores trying to access the memory simultaneously and with little cache available, the accelerator can run out of memory very quickly. This makes the data management and its access pattern is essential on the GPU. Accelerators like to be overloaded with the number of threads, because they can switch between threads very quickly. This allows to hide the memory operations: while some threads wait, others can compute.
Exposing parallelism
The are two types of parallelism tha can be explored. The data parallelism is when the data can be distributed across computational units that can run in parallel. They than process the data applying the same or very simular operation to diffenet data elements. A common example is applying a blur filter to an image — the same function is applied to all the pixels on the image. This parallelism is natural for the GPU, where the same instruction set is executed in multiple threads.
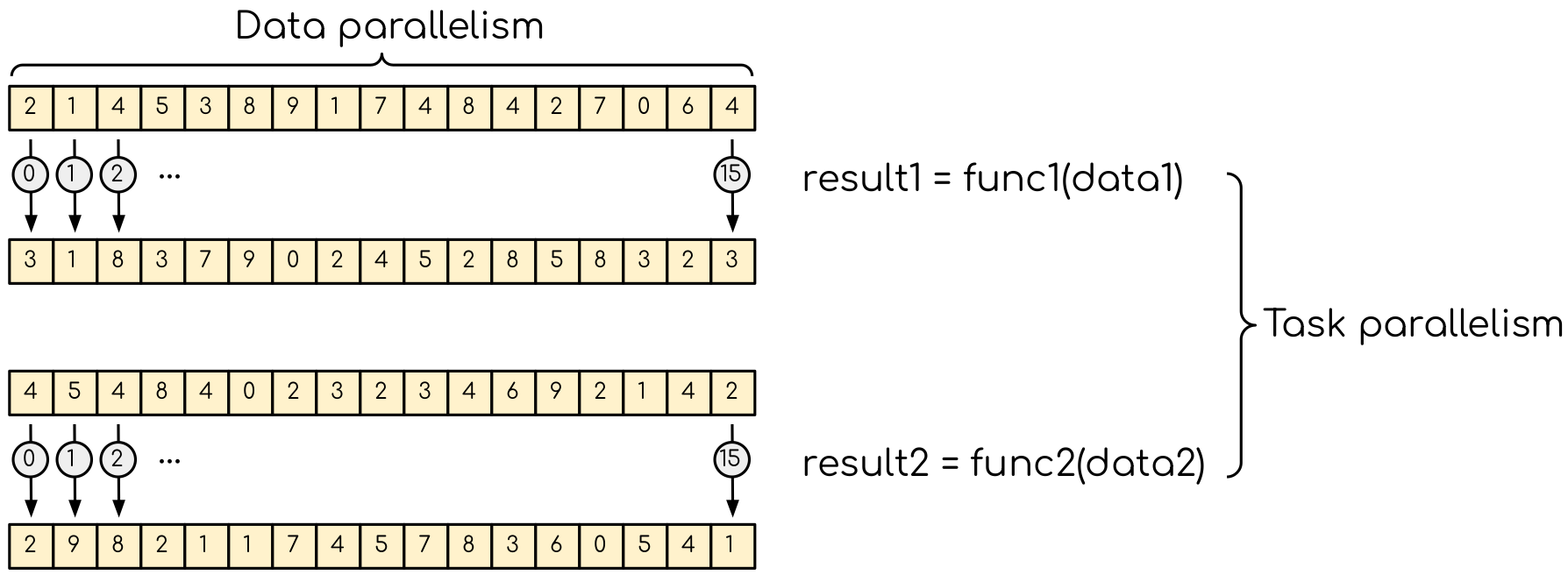
Data parallelism and task parallelism. The data parallelism is when the same operation applies to multiple data (e.g. multiple elements of an array are transformed). The task parallelism implies that there are more than one independent task that, in principle, can be executed in parallel.
Data parallelism can usually be explored by the GPUs quite easily. The most basic approach would be finding a loop over many data elements and converting it into a GPU kernel. If the number of elements in the data set if fairly large (tens or hundred of thousands elements), the GPU should perform quite well. Although it would be odd to expect absolute maximum performance from such a naive approach, it is often the one to take. Getting absolute maximum out of the data parallelism requires good understanding of how GPU works.
Another type of parallelism is a task parallelism. This is when an application consists of more than one task that requiring to perform different operations with (the same or) different data. An example of task parallelism is cooking: slicing vegetables and grilling are very different tasks and can be done at the same time. Note that the tasks can consume totally different resources, which also can be explored.
Using GPUs
From less to more difficult:
Use existing GPU applications
Use accelerated libraries
Directive based methods
OpenMP
OpenACC
Use lower level language
CUDA
HIP
OpenCL
SYCL
Summary
GPUs are highly parallel devices that can execute certain parts of the program in many parallel threads.
In order to use the GPU efficiency, one has to split their task in many sub-tasks that can run simultaneously.
Running your application asynchronously allows to overlap different tasks, including data transfers, GPU and CPU compute kernel.
Language extensions, such as CUDA, HIP, can give more performance, but harder to use.
Directive based methods are easy to implement, but can not leverage all the GPU capabilities.