Launching the GPU kernel
CUDA kernels
Now we learned how to interact with CUDA API, we can ask the GPU to execute a code.
GPU is an accelerator, which means that it was designed to be used alongside the conventional CPU.
Any code that uses GPU must have two parts: one that is executed on a CPU and one that is ported to the GPU.
CPU still controls the workflow, with GPU helping out with the more compute-intensive parts of the workflow.
This is why the CPU is normally referred to as a host, and GPU — as a device.
With this hardware structure, the API should have a means to switch from CPU to GPU execution.
This is done using special functions, called kernels.
To separate these functions from usual functions, they are marked by function specifier __global__:
__global__ void gpu_kernel(..)
What __global__ essentially means is that the function should be called from the host code, but will be executed on the device.
Since this function will be executed in many threads, the return value must be void: otherwise it would not be clear which of the threads should do the return.
The rest of the function definition is the same as with any C/C++ function: its name has the same limitations as a normal C function, it can have any number of arguments of any type, it is even can be templated.
Since the call of the kernel function happens in the host code but it is executed on the device, this place in the code marks a transition from single-thread execution to a many-thread execution.
One can think of it being a loop, each step of which is executed simultaneously.
As in loop, one needs an index, to differentiate the threads.
Here it gets a little bit complicated and we need to step back and re-iterate on how the GPUs are organized on a hardware level.
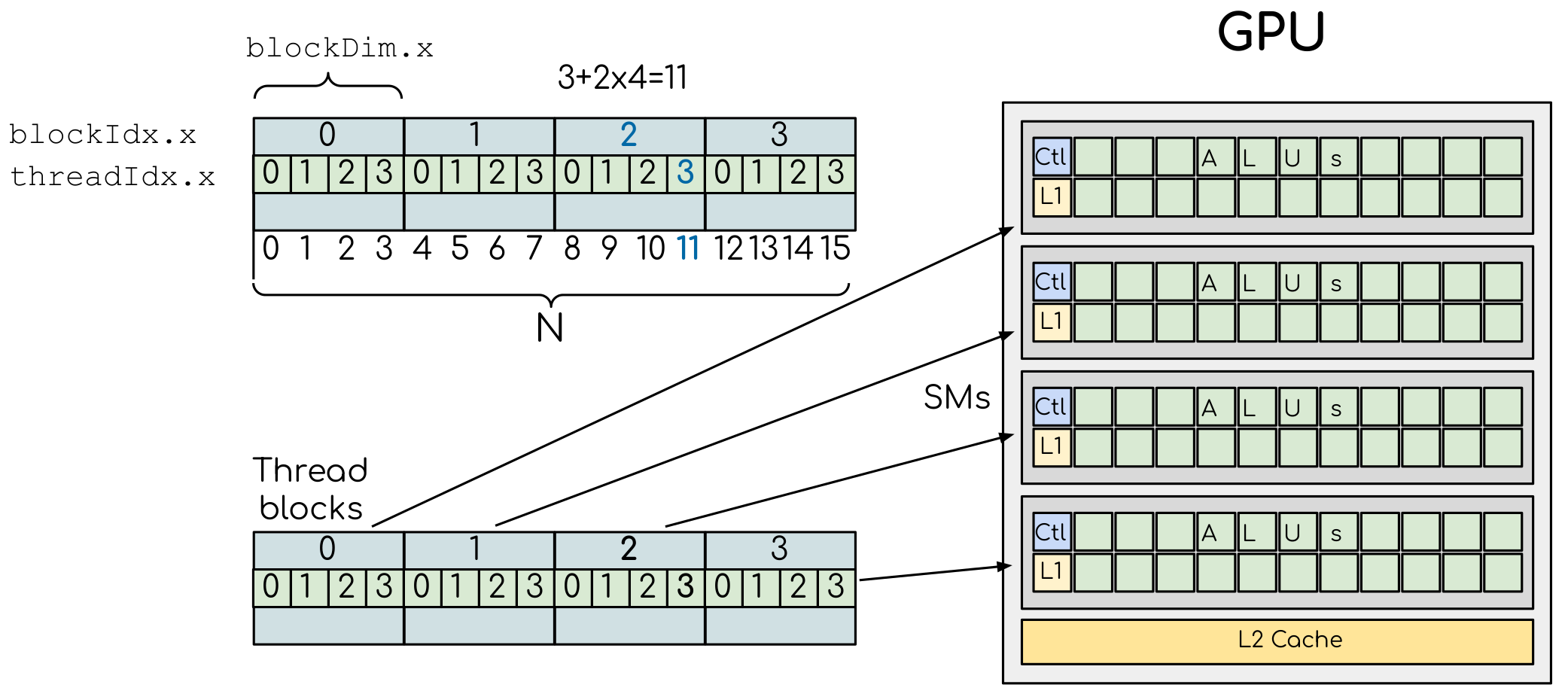
A simple example of the division of threads (green squares) in blocks (cyan rectangles). The equally-sized blocks contain four threads each. The thread index starts from zero in each block. Hence the “global” thread index should be computed from the thread index, block index and block size. This is explained for the thread #3 in block #2 (blue numbers). The thread blocks are mapped to SMs for execution, with all threads within a block executing on the same device. The number of threads within one block does not have to be equal to the number of execution units within multiprocessor. In fact, GPUs can switch between software threads very efficiently, putting threads that currently wait for the data on hold and releasing the resources for threads that are ready for computations. For efficient GPU utilization, the number of threads per block has to be couple of factors higher than the number of computing units on the multiprocessor. Same is true for the number of thread blocks, which can and should be higher than the number of available multiprocessor in order to use the GPU computational resources efficiently.
The GPU contains several Streaming Modules (SMs, or multiprocessors), each with many compute units (see Figure above). Every compute unit can execute commands. So the entire GPU is first divided into streaming modules (or multiprocessors) and each multiprocessor contains many execution units. To reflect this hierarchy on a software level, threads are grouped in identically sized blocks. Each block is assigned into a streaming module for execution. This collection of the thread blocks is usually called “grid”, which also can be multi-dimensional.
Although it may seem a bit complicated at the beginning, the grouping of threads open extra opportunities for synchronization and data exchange. Since threads in a block are executed on a same SM, they can shared the data and can do fast communications. This can be leveraged when designing and optimizing the code for GPU execution, and we will touch this topic later.
Given that the threads on a GPU are organized in a hierarchical manner, the global index of a thread should be computed from its in-block index, the index of execution block and the execution block size. To get the global thread index, one can start the kernel function with:
__global__ void gpu_kernel(..)
{
int i = threadIdx.x + blockIdx.x*blockDim.x;
}
Here, threadIdx.x, blockIdx.x and blockDim.x are internal variables that are always available inside the device function.
They are, respectively, index of thread in a block, index of the block and the size of the block.
Here, we use one-dimensional arrangement of blocks and threads (hence, the .x).
More on multi-dimensional grids and CUDA built-in simple types later, for now we assume that the rest of the components equal to 1.
Since the index i is unique for each thread in an entire grid, it is usually called “global” index.
Global index can than be used to identify the GPU thread and assign a data elements to it.
For example, if we are applying the same function on different data elements in an array, we can use the global index to identify the element of this array for a particular thread.
In a CPU code, this would normally be done in a loop over all consecutive values in an array.
In a GPU code, we assign a thread to each element of the array.
Now the kernel is defined, we can call it from the host code.
Since the kernel will be executed in a grid of threads, so the kernel launch should be supplied with the configuration of the grid.
In CUDA this is done by adding kernel cofiguration, <<<numBlocks, threadsPerBlock>>>, to the function call:
gpu_kernel<<<numBlocks, threadsPerBlock>>>(..)
Here, numBlocks is the total number of thread blocks in the grid, threadsPerBlock is the number of threads in a single block.
Note, that these values can be integers, or can be two-dimensional of three-dimensional vectors, if this is more suitable for the kernel.
More on that later.
In case of one-dimensional grid, the kernel configuration can be specified by two integer values.
The threadsPerBlock can be arbitrary chosen.
It should be larger that the number of CUDA cores in the SM to fully occupy the device, but lower than the limit of 1024 (see the technical specifications).
Values of 256 or 512 are frequently used.
The total number of threads that will be created is the multiple of numBlocks and threadsPerBlock.
Kernels are asynchronous
In CUDA, the execution of the kernel is asynchronous. This means that the execution will return to the CPU immediately after the kernel is launched. Later we will see how this can be used to our advantage, since it allows us to keep CPU busy while GPU is executing the kernel. But for the following example we will need to explicitly ask the CPU to wait until the GPU is done with the kernel execution. This can be done with the following function from CUDA API:
__host__ __device__ cudaError_t cudaDeviceSynchronize()
We are already familiar with __host__ and __device__ specifiers: this function can be used in both host and device code.
As usual, the return type is cudaError_t, which may indicate that there was an error in execution and the function does not take any arguments.
This is all we are going to need for our next example, in which we are going to ask a thread to print its global index.
Exercise
Why the order of the threads in the output is random?
Try executing the program several times to see if there is a pattern in the way the output is printed. Try increasing the number of threads per block to 64. Can you notice anything interesting in the order of threads within the block?
Solution
Driver assigns the threads to multiprocessors by blocks. There is no guarantee that the first multiprocessor will complete its operations before the second. The output is printed as the threads execution reach the corresponding line of the code and which one will be there faster depends on many different factors. Within the block, the order seems to be consistent if the block size is 32. When the number is larger, you can notice that the order of threads within chunks of 32 threads is consistent. However, the order of this chunks can vary. On NVIDIA GPU, execution is performed by so-called warps of threads and the size of a warp is exactly 32 for all NVIDIA GPUs. Within the warp, the threads execute the same command simultaneously. This is why the order within warp is consistent. And this is also why one has to be very careful with thread divergency within warp. Even if just one thread diverges within warp, the rest of the threads will wait until the divergent thread completes its operations.