Introduction
Overview
Teaching: 40 min
Exercises: 15 minQuestions
What is Deep Learning?
When does it make sense to use and not use Deep Learning?
When is it successful?
What are the tools involved?
What is the workflow for Deep Learning?
Why did we choose to use Keras in this lesson?
Objectives
Recall the sort of problems for which Deep Learning is a useful tool
List some of the available tools for Deep Learning
Recall the steps of a Deep Learning workflow
Explain why it is important to test the accuracy of Deep Learning system.
Identify the inputs and outputs of a Deep Learning system.
Test that we’ve correctly installed the Keras, Seaborn and Sklearn libraries
What is Deep Learning?
Deep Learning, Machine Learning and Artificial Intelligence
Deep Learning (DL) is just one of many techniques collectively known as machine learning. Machine learning (ML) refers to techniques where a computer can “learn” patterns in data, usually by being shown numerous examples to train it. People often talk about machine learning being a form of artificial intelligence (AI). Definitions of artificial intelligence vary, but usually involve having computers mimic the behaviour of intelligent biological systems. Since the 1950s many works of science fiction have dealt with the idea of an artificial intelligence which matches (or exceeds) human intelligence in all areas. Although there have been great advances in AI and ML research recently we can only come close to human like intelligence in a few specialist areas and are still a long way from a general purpose AI. The image below shows some differences between artificial intelligence, Machine Learning and Deep Learning.
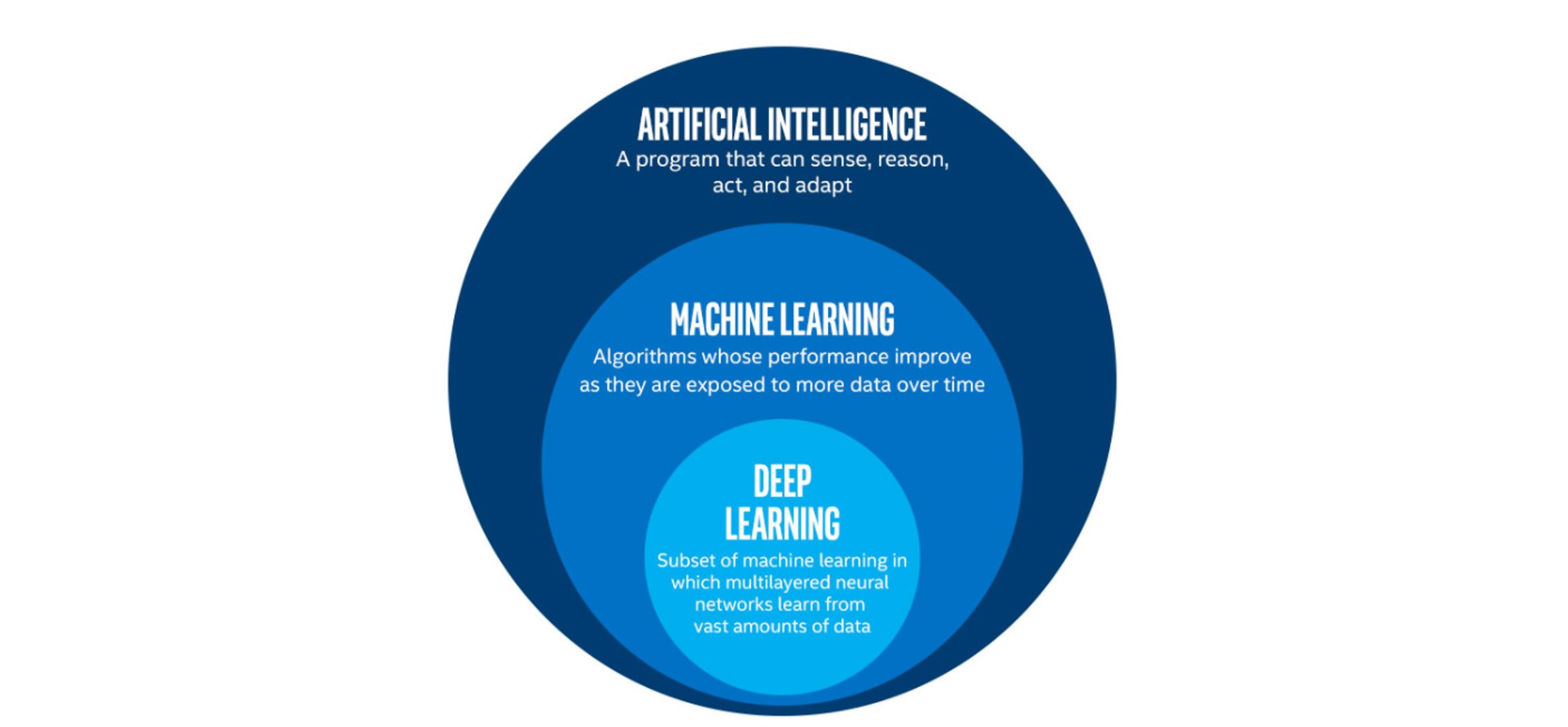 The image above is by Tukijaaliwa, CC BY-SA 4.0, via Wikimedia Commons, original source
The image above is by Tukijaaliwa, CC BY-SA 4.0, via Wikimedia Commons, original source
{kind=link}
Neural Networks
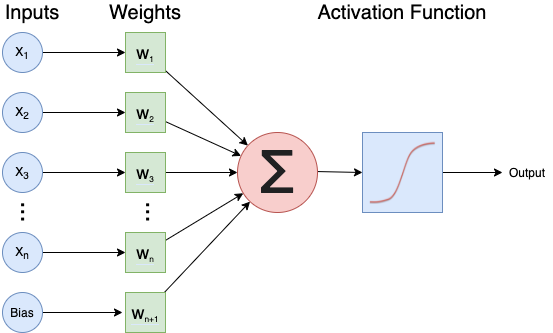
A neural network is an artificial intelligence technique loosely based on the way neurons in the brain work. A neural network consists of connected computational units called neurons. Each neuron …
- has one or more inputs, e.g. input data expressed as floating point numbers
- most of the time, each neuron conducts 3 main operations:
- take the weighted sum of the inputs
- add an extra constant weight (i.e. a bias term) to this weighted sum
- apply a non-linear function to the output so far (using a predefined activation function)
- return one output value, again a floating point number
Multiple neurons can be joined together by connecting the output of one to the input of another. These connections are associated with weights that determine the ‘strength’ of the connection, the weights are adjusted during training. In this way, the combination of neurons and connections describe a computational graph, an example can be seen in the image below. In most neural networks neurons are aggregated into layers. Signals travel from the input layer to the output layer, possibly through one or more intermediate layers called hidden layers. The image below shows an example of a neural network with three layers, each circle is a neuron, each line is an edge and the arrows indicate the direction data moves in.
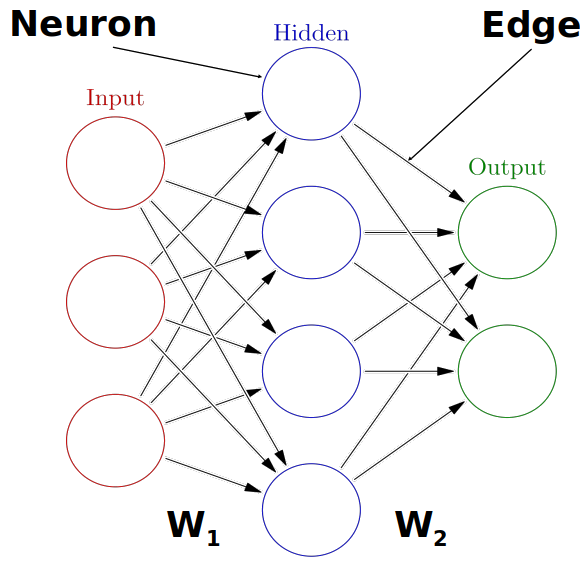 The image above is by Glosser.ca, CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0, via Wikimedia Commons, original source
The image above is by Glosser.ca, CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0, via Wikimedia Commons, original source
{kind=link}
Neural networks aren’t a new technique, they have been around since the late 1940s. But until around 2010 neural networks tended to be quite small, consisting of only 10s or perhaps 100s of neurons. This limited them to only solving quite basic problems. Around 2010 improvements in computing power and the algorithms for training the networks made much larger and more powerful networks practical. These are known as deep neural networks or Deep Learning.
Deep Learning requires extensive training using example data which shows the network what output it should produce for a given input. One common application of Deep Learning is classifying images. Here the network will be trained by being “shown” a series of images and told what they contain. Once the network is trained it should be able to take another image and correctly classify its contents. But we are not restricted to just using images, any kind of data can be learned by a Deep Learning neural network. This makes them able to appear to learn a set of complex rules only by being shown what the inputs and outputs of those rules are instead of being taught the actual rules. Using these approaches Deep Learning networks have been taught to play video games and even drive cars. The data on which networks are trained usually has to be quite extensive, typically including thousands of examples. For this reason they are not suited to all applications and should be considered just one of many machine learning techniques which are available.
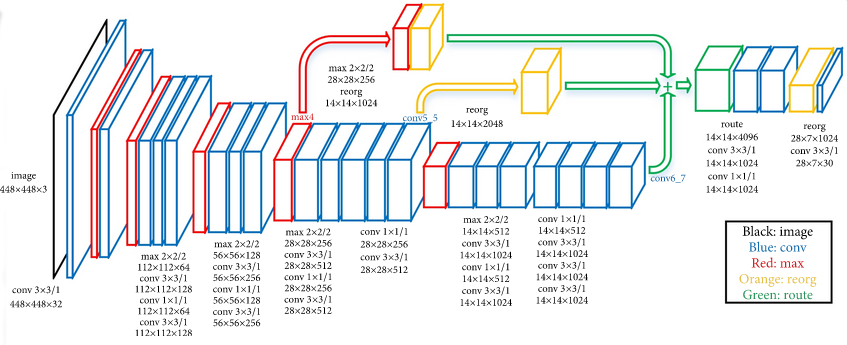
While traditional “shallow” networks might have had between three and five layers, deep networks often have tens or even hundreds of layers. This leads to them having millions of individual weights. The image below shows a diagram of all the layers (there are too many neurons to draw them all) on a Deep Learning network designed to detect pedestrians in images. The input (left most) layer of the network is an image and the final (right most) layer of the network outputs a zero or one to determine if the input data belongs to the class of data we’re interested in. This image is from the paper “An Efficient Pedestrian Detection Method Based on YOLOv2” by Zhongmin Liu, Zhicai Chen, Zhanming Li, and Wenjin Hu published in Mathematical Problems in Engineering, Volume 2018
What sort of problems can Deep Learning solve?
- Pattern/object recognition
- Segmenting images (or any data)
- Translating between one set of data and another, for example natural language translation.
- Generating new data that looks similar to the training data, often used to create synthetic datasets, art or even “deepfake” videos.
- This can also be used to give the illusion of enhancing data, for example making images look sharper, video look smoother or adding colour to black and white images. But beware of this, it is not an accurate recreation of the original data, but a recreation based on something statistically similar, effectively a digital imagination of what that data could look like.
Examples of Deep Learning in Research
Here are just a few examples of how Deep Learning has been applied to some research problems. Note: some of these articles might be behind paywalls.
- Detecting COVID-19 in chest X-ray images
- Forecasting building energy load
- Protein function prediction
- Simulating Chemical Processes
- Help to restore ancient murals
What sort of problems can’t Deep Learning solve?
- Any case where only a small amount of training data is available.
- Tasks requiring an explanation of how the answer was arrived at.
- Classifying things which are nothing like their training data.
What sort of problems can Deep Learning solve, but shouldn’t be used for?
Deep Learning needs a lot of computational power, for this reason it often relies on specialised hardware like graphical processing units (GPUs). Many computational problems can be solved using less intensive techniques, but could still technically be solved with Deep Learning.
The following could technically be achieved using Deep Learning, but it would probably be a very wasteful way to do it:
- Logic operations, such as computing totals, averages, ranges etc. (see this example applying Deep Learning to solve the “FizzBuzz” problem often used for programming interviews)
- Modelling well defined systems, where the equations governing them are known and understood.
- Basic computer vision tasks such as edge detection, decreasing colour depth or blurring an image.
Deep Learning Problems Exercise
Which of the following would you apply Deep Learning to?
- Recognising whether or not a picture contains a bird.
- Calculating the median and interquartile range of a dataset.
- Identifying MRI images of a rare disease when only one or two example images available for training.
- Identifying people in pictures after being trained only on cats and dogs.
- Translating English into French.
Solution
- and 5 are the sort of tasks often solved with Deep Learning.
- is technically possible but solving this with Deep Learning would be extremely wasteful, you could do the same with much less computing power using traditional techniques.
- will probably fail because there’s not enough training data.
- will fail because the Deep Learning system only knows what cats and dogs look like, it might accidentally classify the people as cats or dogs.
How much data do you need for Deep Learning?
The rise of Deep Learning is partially due to the increased availability of very large datasets. But how much data do you actually need to train a Deep Learning model? Unfortunately, this question is not easy to answer. It depends, among other things, on the complexity of the task (which you often don’t know beforehand), the quality of the available dataset and the complexity of the network. For complex tasks with large neural networks, we often see that adding more data continues to improve performance. However, this is also not a generic truth: if the data you add is too similar to the data you already have, it will not give much new information to the neural network.
In case you have too little data available to train a complex network from scratch, it is sometimes possible to use a pretrained network that was trained on a similar problem. Another trick is data augmentation, where you expand the dataset with artificial data points that could be real. An example of this is mirroring images when trying to classify cats and dogs. An horizontally mirrored animal retains the label, but exposes a different view.
Deep Learning workflow
To apply Deep Learning to a problem there are several steps we need to go through:
1. Formulate/ Outline the problem
Firstly we must decide what it is we want our Deep Learning system to do. Is it going to classify some data into one of a few categories? For example if we have an image of some hand written characters, the neural network could classify which character it is being shown. Or is it going to perform a prediction? For example trying to predict what the price of something will be tomorrow given some historical data on pricing and current trends.
2. Identify inputs and outputs
Next we need to identify what the inputs and outputs of the neural network will be. This might require looking at our data and deciding what features of the data we can use as inputs. If the data is images then the inputs could be the individual pixels of the images.
For the outputs we’ll need to look at what we want to identify from the data. If we are performing a classification problem then typically we will have one output for each potential class.
3. Prepare data
Many datasets aren’t ready for immediate use in a neural network and will require some preparation. Neural networks can only really deal with numerical data, so any non-numerical data (for example words) will have to be somehow converted to numerical data.
Next we’ll need to divide the data into multiple sets. One of these will be used by the training process and we’ll call it the training set. Another will be used to evaluate the accuracy of the training and we’ll call that one the test set. Sometimes we’ll also use a 3rd set known as a validation set to check our results after training is complete.
4. Choose a pre-trained model or build a new architecture from scratch
Often we can use an existing neural network instead of designing one from scratch. Training a network can take a lot of time and computational resources. There are a number of well publicised networks which have been shown to perform well at certain tasks, if you know of one which already does a similar task well then it makes sense to use one of these.
If instead we decide we do want to design our own network then we need to think about how many input neurons it will have, how many hidden layers and how many outputs, what types of layers we use (we’ll explore the different types later on). This will probably need some experimentation and we might have to try tweaking the network design a few times before we see acceptable results.
5. Choose a loss function and optimizer
The loss function tells the training algorithm how far away the predicted value was from the true value. We’ll look at choosing a loss function in more detail later on.
The optimizer is responsible for taking the output of the loss function and then applying some changes to the weights within the network. It is through this process that the “learning” (adjustment of the weights) is achieved.
6. Train the model
We can now go ahead and start training our neural network. We’ll probably keep doing this for a given number of iterations through our training dataset (referred to as epochs) or until the loss function gives a value under a certain threshold. The graph below show the loss against the number of epochs, generally the loss will go down with each epoch, but occasionally it will see a small rise.

7. Perform a Prediction/Classification
After training the network we can use it to perform predictions. This is the mode you would use the network in after you have fully trained it to a satisfactory performance. Doing predictions on a special hold-out set is used in the next step to measure the performance of the network.
8. Measure Performance
Once we think the network is performing well we want to measure its performance. To do this we can use some additional data that wasn’t part of the training, this is known as a validation set. There are many different methods available for doing this and which one is best depends on the type of task we are attempting. These metrics are often published as an indication of how well our network performs.
9. Tune Hyperparameters
Hyperparameters are all the parameters set by the person configuring the machine learning instead of those learned by the algorithm itself. The Hyperparameters include the number of epochs or the parameters for the optimizer. It might be necessary to adjust these and re-run the training many times before we are happy with the result.
10. Share Model
Now that we have a trained network that performs at a level we are happy with we can go and use it on real data to perform a prediction. At this point we might want to consider publishing a file with both the architecture of our network and the weights which it has learned (assuming we didn’t use a pre-trained network). This will allow others to use it as as pre-trained network for their own purposes and for them to (mostly) reproduce our result.
Deep Learning workflow exercise
Think about a problem you’d like to use Deep Learning to solve.
- What do you want a Deep Learning system to be able to tell you?
- What data inputs and outputs will you have?
- Do you think you’ll need to train the network or will a pre-trained network be suitable?
- What data do you have to train with? What preparation will your data need? Consider both the data you are going to predict/classify from and the data you’ll use to train the network.
Discuss your answers with the group or the person next to you.
Deep Learning Libraries
There are many software libraries available for Deep Learning including:
TensorFlow
TensorFlow was developed by Google and is one of the older Deep Learning libraries, ported across many languages since it was first released to the public in 2015. It is very versatile and capable of much more than Deep Learning but as a result it often takes a lot more lines of code to write Deep Learning operations in TensorFlow than in other libraries. It offers (almost) seamless integration with GPU accelerators and Google’s own TPU (Tensor Processing Unit) chips that are built specially for machine learning.
PyTorch
PyTorch was developed by Facebook in 2016 and is a popular choice for Deep Learning applications. It was developed for Python from the start and feels a lot more “pythonic” than TensorFlow. Like TensorFlow it was designed to do more than just Deep Learning and offers some very low level interfaces. Like TensorFlow it’s also very easy to integrate PyTorch with a GPU. In many benchmarks it out performs the other libraries.
Keras
Keras is designed to be easy to use and usually requires fewer lines of code than other libraries. We have chosen it for this workshop for that reason. Keras can actually work on top of TensorFlow (and several other libraries), hiding away the complexities of TensorFlow while still allowing you to make use of their features.
The performance of Keras is sometimes not as good as other libraries and if you are going to move on to create very large networks using very large datasets then you might want to consider one of the other libraries. But for many applications the performance difference will not be enough to worry about and the time you’ll save with simpler code will exceed what you’ll save by having the code run a little faster.
Keras also benefits from a very good set of online documentation and a large user community. You will find that most of the concepts from Keras translate very well across to the other libraries if you wish to learn them at a later date.
Installing Keras and other dependencies
Follow the instructions in the setup document to install Keras, Seaborn and Sklearn.
Testing Keras Installation
Lets check you have a suitable version of Keras installed. Open up a new Jupyter notebook or interactive python console and run the following commands:
from tensorflow import keras print(keras.__version__)Solution
You should get a version number reported. At the time of writing 2.4.0 is the latest version.
2.4.0
Testing Seaborn Installation
Lets check you have a suitable version of seaborn installed. In your Jupyter notebook or interactive python console run the following commands:
import seaborn print(seaborn.__version__)Solution
You should get a version number reported. At the time of writing 0.11.1 is the latest version.
0.11.1
Testing Sklearn Installation
Lets check you have a suitable version of sklearn installed. In your Jupyter notebook or interactive python console run the following commands:
import sklearn print(sklearn.__version__)Solution
You should get a version number reported. At the time of writing 0.24.1 is the latest version.
0.24.1
Key Points
Machine learning is the process where computers learn to recognise patterns of data.
Artificial neural networks are a machine learning technique based on a model inspired by groups of neurons in the brain.
Artificial neural networks can be trained on example data.
Deep Learning is a machine learning technique based on using many artificial neurons arranged in layers.
Deep Learning is well suited to classification and prediction problems such as image recognition.
To use Deep Learning effectively we need to go through a workflow of: defining the problem, identifying inputs and outputs, preparing data, choosing the type of network, choosing a loss function, training the model, tuning Hyperparameters, measuring performance before we can classify data.
Keras is a Deep Learning library that is easier to use than many of the alternatives such as TensorFlow and PyTorch.