Why OpenMP offloading?
Questions
When and why should I use OpenMP offloading in my code?
Objectives
Understand shared parallel model
Understand program execution model
Understand basic constructs
Prerequisites
Basic C or FORTRAN
Computing in parallel
The underlying idea of parallel computing is to split a computational problem into smaller subtasks. Many subtasks can then be solved simultaneously by multiple processing units.
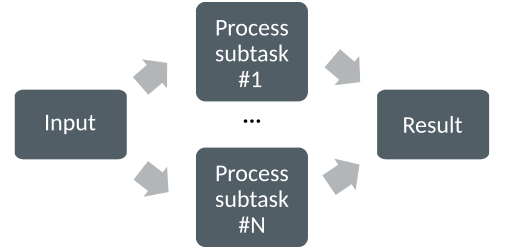
Computing in parallel.
How a problem is split into smaller subtasks depends fully on the problem. There are various paradigms and programming approaches how to do this.
Distributed- vs. Shared-Memory Architecture
Most of computing problems are not trivially parallelizable, which means that the subtasks need to have access from time to time to some of the results computed by other subtasks. The way subtasks exchange needed information depends on the available hardware.
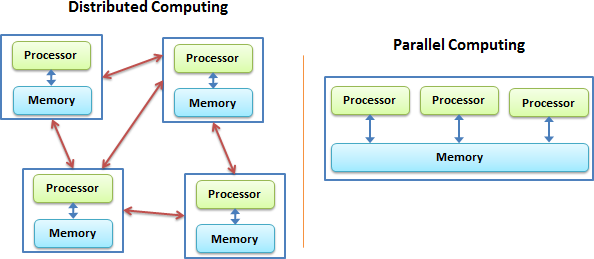
Distributed- vs shared-memory parallel computing.
In a distributed memory environment each computing unit operates independently from the others. It has its own memory and it cannot access the memory in other nodes. The communication is done via network and each computing unit runs a separate copy of the operating system. In a shared memory machine all computing units have access to the memory and can read or modify the variables within.
Processes and threads
The type of environment (distributed- or shared-memory) determines the programming model. There are two types of parallelism possible, process based and thread based.

For distributed memory machines, a process-based parallel programming model is employed. The processes are independent execution units which have their own memory address spaces. They are created when the parallel program is started and they are only terminated at the end. The communication between them is done explicitly via message passing like MPI.
On the shared memory architectures it is possible to use a thread based parallelism. The threads are light execution units and can be created and destroyed at a relatively small cost. The threads have their own state information but they share the same memory adress space. When needed the communication is done though the shared memory.
Both approaches have their advantages and disadvantages. Distributed machines are relatively cheap to build and they have an “infinite ” capacity. In principle one could add more and more computing units. In practice the more computing units are used the more time consuming is the communication. The shared memory systems can achive good performance and the programing model is quite simple. However they are limited by the memory capacity and by the access speed. In addition in the shared parallel model it is much easier to create race conditions.
OpenMP
OpenMP is de facto standard for threaded based parallelism. It is relatively easy to implement. The whole technology suite contains the library routines, the compiler directives and environment variables. The parallelization is done providing “hints” (directives) about the regions of code which are targeted for parallelization. The compiler then chooses how to implement these hints as best as possible. The compiler directives are comments in Fortran and pragmas in C/C++. If there is no OpenMP support in the system they become comments and the code works just as any other serial code.
Execution model
OpenMP API uses the fork-join model of parallel execution. The program begins as a single thread of execution, the master thread. Everything is executed sequentially until the first parallel region construct is encountered.
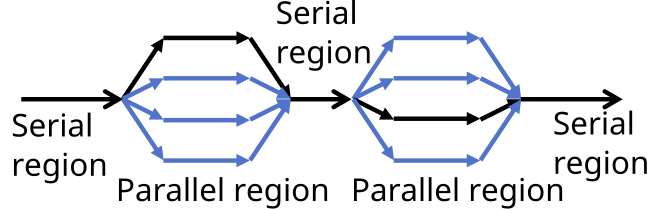
When a parallel region is encountered, master thread creates a group of threads, becomes the master of this group of threads, and is assigned the thread index 0 within the group. There is an implicit barrier at the end of the parallel regions.
OpenMP Memory Model
In the OpenMP API supports a relaxed-consistency shared-memory model. The global memory is a shared place where all threads can store and retrieve variables. In addition to it each thread has its own temporary view of the memory. The temporary view of memory can represent any kind of intervening structure, such as machine registers, cache, or other local storage, between the thread and the memory it allows the thread to cache variables and to avoid going to memory for every reference to a variable. The temporary view of memory is not necesseraly consistent with that of other threads. Finally each thread has access to a part of memory that can not be access by the other threads, the threadprivate memory.
Inside a parallel region there are two kinds of access of the variables, shared and private. Each reference to a shared variable in the structured block becomes a reference to the original variable, while for each private variable referenced in the structured block, a new version of the original variable is created in memory for each thread. In the case of nested parallel regions a variable which private can be made shared to the inner parallel region.
OpenMP Directives
In OpenMP the compiler directives are specified by using #pragma in C/C++ or as special comments identified by unique sentinels in Fortran. Compilers can ingnore the OpenMP directives if the support for OpenMP is not enabled,
Here are some prototypes of OpenMP directives:
#pragma omp directive [clauses]!$ omp directive [clauses]
Parallel regions
The compiler directives are used for various purposes: for thread creation, workload distribution (work sharing), data-environment management, serializing sections of code or for synchronization of work among the threads. The parallel regions are created using the parallel construct. When this construct is encounter additional thread are forked to carry out the work enclose in it.

Outside of a parallel region there is only one threas, while inside there are N threads
All threads inside the construct execute the same, there is not work sharing yet.
#include <stdio.h> int main(int argc, char argv[]){ #pragma omp parallel { printf("Hello world!"); } }program hello integer :: omp_rank !$omp parallel print *, 'Hello world! !$omp end parallel end program hello
Note that the value of the output from the printf/print can be all mixed up.
Work sharing
In a parallel region all threads execute the same code. The division of work can be done by the user, based on the thread id (or thread rank) different subtasks can be assigned to different threads, or by using the work-sharing constructs:
omp for or omp do: used to split up loop iterations among the threads, also called loop constructs.
sections: assigning consecutive but independent code blocks to different threads
single: specifying a code block that is executed by only one thread, a barrier is implied in the end
master : similar to single, but the code block will be executed by the master thread only and no barrier implied in the end.
task: allows to create units of work dynamically for parallelizing irregular algorithms such as recursive algorithms.
workshare: divides the execution of the enclosed structured block into separate units of work. Each unit of work is executied by one thread. (Fortran only)
simd: indicates that multiple iterations of the loop can be executed concurrently using SIMD instructions
Example of a trivially parallelizable problem using the loop workshare construct:
#include <stdio.h> int main(int argc, char argv[]){ int a[1000]; #pragma omp parallel { #pragma omp for for (int i = 0; i < 1000; i++) { a[i] = 2 * i; } } }program hello integer :: a[1000] !$omp parallel !$omp do do i=0,999 a(i+1)=2*i enddo !$omp end do !$omp end parallel end program hello In this example OpenMP distributes the work among the threads by dividing the number of interations in the loop by the number of threads (default behaviour). At the end of the loop construct there is an implicit synchronization.
The constructs can be combined if one is imediatly nested inside another construct.
Clauses
Together with compiler directives, OpenMP provides clauses that can used to control the parallelism of regions of code. The clauses specify additional behaviour the user wants to occur and they refere to how the variables are visible to the threads (private or shared), synchronization, scheduling, control, etc. The clauses are appended in the code to the directives. Below is an list of many types of clauses available to the programmers:
Data sharing attribute clauses
By default all variables are shared. Sometimes private variables are necessary to avoid race conditions
shared: the data declared outside a parallel region is shared, which means visible and accessible by all threads simultaneously. By default, all variables in the work sharing region are shared except the loop iteration counter.
private: the data declared within a parallel region is private to each thread, which means each thread will have a local copy and use it as a temporary variable. A private variable is not initialized and the value is not maintained for use outside the parallel region. By default, the loop iteration counters in the OpenMP loop constructs are private.
default: allows the programmer to state that the default data scoping within a parallel region will be either shared, or none for C/C++, or shared, firstprivate, private, or none for Fortran. The none option forces the programmer to declare each variable in the parallel region using the data sharing attribute clauses.
firstprivate: like private except initialized to original value.
lastprivate: like private except original value is updated after construct.
reduction: a safe way of joining work from all threads after construct.
Bellow is an example of reduction code without race condition:
#pragma omp parallel for shared(x,y,n) private(i) reduction(+:asum){ for(i=0; i < n; i++) { asum = asum + x[i] * y[i]; } }!$omp parallel do shared(x,y,n) private(i) reduction(+:asum) do i = 1, n asum = asum + x(i)*y(i) end do !$omp end parallel
Synchronization clauses
critical: the enclosed code block will be executed by only one thread at a time, and not simultaneously executed by multiple threads. It is often used to protect shared data from race conditions.
atomic: the memory update (write, or read-modify-write) in the next instruction will be performed atomically. It does not make the entire statement atomic; only the memory update is atomic. A compiler might use special hardware instructions for better performance than when using critical.
ordered: the structured block is executed in the order in which iterations would be executed in a sequential loop
barrier: each thread waits until all of the other threads of a team have reached this point. A work-sharing construct has an implicit barrier synchronization at the end.
nowait: specifies that threads completing assigned work can proceed without waiting for all threads in the team to finish. In the absence of this clause, threads encounter a barrier synchronization at the end of the work sharing construct.
Scheduling clauses
schedule (type, chunk): This is useful if the work sharing construct is a do-loop or for-loop. The iterations in the work sharing construct are assigned to threads according to the scheduling method defined by this clause. The three types of scheduling are:
static: Here, all the threads are allocated iterations before they execute the loop iterations. The iterations are divided among threads equally by default. However, specifying an integer for the parameter chunk will allocate chunk number of contiguous iterations to a particular thread.
dynamic: Here, some of the iterations are allocated to a smaller number of threads. Once a particular thread finishes its allocated iteration, it returns to get another one from the iterations that are left. The parameter chunk defines the number of contiguous iterations that are allocated to a thread at a time.
guided: A large chunk of contiguous iterations are allocated to each thread dynamically (as above). The chunk size decreases exponentially with each successive allocation to a minimum size specified in the parameter chunk
IF control
if: This will cause the threads to parallelize the task only if a condition is met. Otherwise the code block executes serially.
Initialization
firstprivate: the data is private to each thread, but initialized using the value of the variable using the same name from the master thread.
lastprivate: the data is private to each thread. The value of this private data will be copied to a global variable using the same name outside the parallel region if current iteration is the last iteration in the parallelized loop. A variable can be both firstprivate and lastprivate.
threadprivate: The data is a global data, but it is private in each parallel region during the runtime. The difference between threadprivate and private is the global scope associated with threadprivate and the preserved value across parallel regions.
Reduction
reduction (operator | intrinsic : list): the variable has a local copy in each thread, but the values of the local copies will be summarized (reduced) into a global shared variable. This is very useful if a particular operation (specified in operator for this particular clause) on a variable runs iteratively, so that its value at a particular iteration depends on its value at a prior iteration. The steps that lead up to the operational increment are parallelized, but the threads updates the global variable in a thread safe manner. This would be required in parallelizing numerical integration of functions and differential equations, as a common example.
Others
flush: The value of this variable is restored from the register to the memory for using this value outside of a parallel part
master: Executed only by the master thread (the thread which forked off all the others during the execution of the OpenMP directive). No implicit barrier; other team members (threads) not required to reach.
collapse: When more than one loop follows a loop construct it sppecifies how many loops in a nested loop should be collapsed into one large iteration space.
Runtime library routines
The OpenMp includes and extensive suite of run-time routines. They can be used for many purposes: to modify/check the number of threads, detect if the execution context is in a parallel region, how many processors in current system, set/unset locks, timing functions, etc.
The functions definitions are in the omp.h header in C/C++ and in fortran in the omp_lib module. Some very useful routines:
omp_get_num_threads()
omp_get_thread_num()
omp_get_wtime()
#include <omp.h> int main(int argc, char argv[]){ int omp_rank; #pragma omp parallel { omp_rank = omp_get_thread_num(); printf("Hello world! by thread %d", omp_rank); } }program hello use omp_lib integer :: omp_rank !$omp parallel omp_rank = omp_get_thread_num() print *, 'Hello world! by thread ', omp_rank !$omp end parallel end program hello
The portability of the code can be mantained by using the conditional compilation ifdef _OPENMP.
OpenMP environment variables
OpenMP standard defines also a set of environment variables that all implementations have to support. The environment variables are set before the program execution and they are read during program start-up. They can be used to control the execution of the parallel code at run-time. They are used to set the number of threads, specify the binding of the threads or specify how the loop interations are divided.
Setting OpenMP environment variables is done the same way you set any other environment variables. For example:
csh/tcsh: setenv OMP_NUM_THREADS 8
sh/bash: export OMP_NUM_THREADS=8
Here are a few environment variables:
OMP_NUM_THREADS: Number of threads to use
OMP_PROC_BIND: Bind threads to CPUs
OMP_PLACES: Specify the bindings between threads and CPUs
OMP_DISPLAY_ENV: Print the current OpenMP environment info on stderr
Compiling an OpenMP program
In order to use OpenMP the compiler needs to have support for it. The OpenMP support is enabled by adding an extra compiling option:
GNU: -fopenmp
Intel: -qopenmp
Cray: -h omp
PGI: -mp[=nonuma,align,allcores,bind]
Keypoints
OpenMP is the de facto standard for programming shared memory machines
threaded based parallel programming model
fork-join model
global memory, temporary view, thread private memory
parallelism is exposed via directives which are treated as comments if no support
work sharing done via specific constructs
clauses provide additional control
runtime libray provides an extensive suite of routines
environment variables can be used to alter execution features of the the applications