Simple collective communication
Questions
How can all ranks of my program collaborate with messages?
How does collective messaging differ from point-to-point?
Objectives
Know the different kinds of collective message operations
Understand the terminology used in MPI about collective messages
Understand how to combine data from ranks of a communicator in an operation
Introduction
Parallel programs often need to collaborate when passing messages:
To ensure that all ranks have reached a certain point (barrier)
To share data with all ranks (broadcast)
To compute based on data from all ranks (reduce)
To rearrange data across ranks for subsequent computation (scatter, gather)
These can all be done with point-to-point messages. However that requires more code, runs slower, and scales worse that using the optimized collective calls.
There are several other operations that generalize these building blocks:
gathering data from all ranks and delivering the same data to all ranks
all-to-all scatter and gather of different data to all ranks
Finally, MPI supports reduction operations, where a logical or arithmetic operation can be used to efficiently compute while communicating data.
Barrier
An MPI_Barrier call ensures that all ranks arrive at the call before
any of them proceeds past it.

All ranks in the communicator reach the barrier before any continue past it
MPI_Barrier is blocking (ie. does not return until the operation
is complete) and introduces collective synchronization into the
program. This can be useful to allow rank to wait for an external
event (e.g. files being written by another process) before entering
the barrier, rather than have all ranks checking.
When debugging problems in other MPI communication, adding calls to
MPI_Barrier can be useful. However, if a barrier is necessary for
your program to function correctly, that may suggest your
program has a bug!
Parameters
It takes one argument, the communicator over which the barrier operates. All ranks within that communicator must call it or the program will hang waiting for them to do so.
Broadcast
An MPI_Bcast call sends data from one rank to all other ranks.

After the call, all ranks in the communicator agree on the two values sent.
MPI_Bcast is blocking and introduces collective
synchronization into the program.
This can be useful to allow one rank to share values to all other ranks in the communicator. For example, one rank might read a file, and then broadcast the content to all other ranks. This is usually more efficient than having each rank read the same file.
Sends data from one rank to all other ranks
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype,
int root, MPI_Comm comm)
Parameters
All ranks must supply the same value for root, which specifies
the rank of that communicator that provides the values that are
broadcast to all other ranks.
buffer, count, datatype, and comm are similar to those
used for point-to-point communication; all ranks in the communicator
must participate with valid buffers and consistent counts and types.
Reduce
An MPI_Reduce call combines data from all ranks using an operation
and returns values to a single rank.

After the call, the root rank has a value computed by combining a value from each other rank in the communicator with an operation.
MPI_Reduce is blocking and introduces collective
synchronization into the program.
There are several kinds of pre-defined operation, including arithmetic and logical operations. A full list of operations is available in the linked documentation.
This is useful to allow one rank to compute based on values from all
other ranks in the communicator. For example, the maximum value found
over all ranks (and even the rank upon which it was found) can be
returned to the root rank. Often one simply wants a sum, and for that
MPI_SUM is provided.
Combines data from all ranks using an operation and returns values to a single rank.
int MPI_Reduce(const void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op,
int root, MPI_Comm comm)
Parameters
All ranks must supply the same value for root, which specifies
the rank of the process within that communicator that receives the
values send from each process.
sendbuf, count and datatype describe the buffer on
each process from which the data is sent. Only a buffer large
enough to contain the data sent by that process is needed.
recvbuf, count and datatype describe the buffer on the
root process in which the combined data is received. Other
ranks do not need to allocate a receive buffer, and may pass any
values to the call.
All ranks in the communicator must participate with valid send buffers and consistent counts and types.
Allreduce
An MPI_Reduce call combines data from all ranks using an operation
and returns values to all ranks.
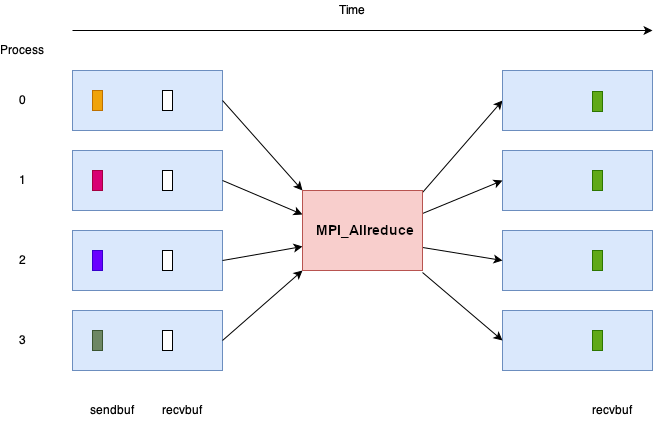
After the call, every rank has a value computed by combining a value from all ranks in the communicator with an operation.
MPI_Allreduce is blocking and introduces collective
synchronization into the program.
The pre-defined operation is the same as in MPI_Reduce.
MPI_Allreduce is useful when the result of MPI_Reduce is
needed on all ranks.
MPI_Allreduce
Combines data from all ranks using an operation and returns values to all ranks.
int MPI_Allreduce(const void *sendbuf, void *recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
Parameters
sendbuf, recvbuf, count and datatype are the same as
in MPI_Reduce.
Exercise: broadcast and reduce
Use a broadcast and observe the results with reduce
You can find a scaffold for the code in the
content/code/day-1/08_broadcast folder. A working solution is in the
solution subfolder. Try to compile with:
mpicc -g -Wall -std=c11 collective-communication-broadcast.c -o collective-communication-broadcast
When you have the code compiling, try to run with:
mpiexec -np 2 ./collective-communication-broadcast
Use clues from the compiler and the comments in the code to change the code so it compiles and runs. Try to get all ranks to report success :-)
Solution
One example of correct calls is:
MPI_Bcast(values_to_broadcast, 2, MPI_INT, rank_of_root, comm); /* ... */ MPI_Reduce(values_to_broadcast, reduced_values, 2, MPI_INT, MPI_SUM, rank_of_root, comm);
Exercise: calculating \(\pi\) using numerical integration
Use broadcast and reduce to compute \(\pi\)
\(\pi = 4 \int_{0}^{1} \frac{1}{1+x^2} dx\).
You can find a scaffold for the code in the
content/code/day-1/09_integrate-pi folder.
Compile with:
mpicc -g -Wall -std=c11 pi-integration.c -o pi-integration
A working solution is in the solution subfolder.
When you have the code compiling, try to run with:
mpiexec -np 4 ./pi-integration 10000
You can try different number of points and see how it affects the result.
Tips when using collective communication
Unlike point-to-point messages, collective communication does not use tags. This is deliberate, because collective communication requires all ranks in the communicator to contribute to the work before any rank will return from the call. There’s no facility for more than one collective communication to run at a time on a communicator, so there’s no need for a tag to clarify which communication is taking place.
Quiz: if one rank calls a reduce, and another rank calls a broadcast, is it a problem?
Yes, always.
No, never.
Yes when they are using the same communicator
Solution
Collectives on the same communicator must be called in the same order by all ranks of that communicator. Collectives on different communicators from disjoint groups of ranks don’t create problems for each other.
See also
Check out the MPI standard
Keypoints
Collective communication requires participation of all ranks in that communicator
Collective communication happens in order and so no tags are needed.