The GPU hardware and software ecosystem
Questions
What are the differences between GPUs and CPUs?
What GPU software stacks are available? What do they provide?
Objectives
Understand the fundamental differences between GPUs and CPUs
Explore the major GPU software suites available, such as CUDA, ROCm, and oneAPI, and gain a basic understanding of them
Instructor note
20 min teaching
0 min exercises
Overview of GPU hardware
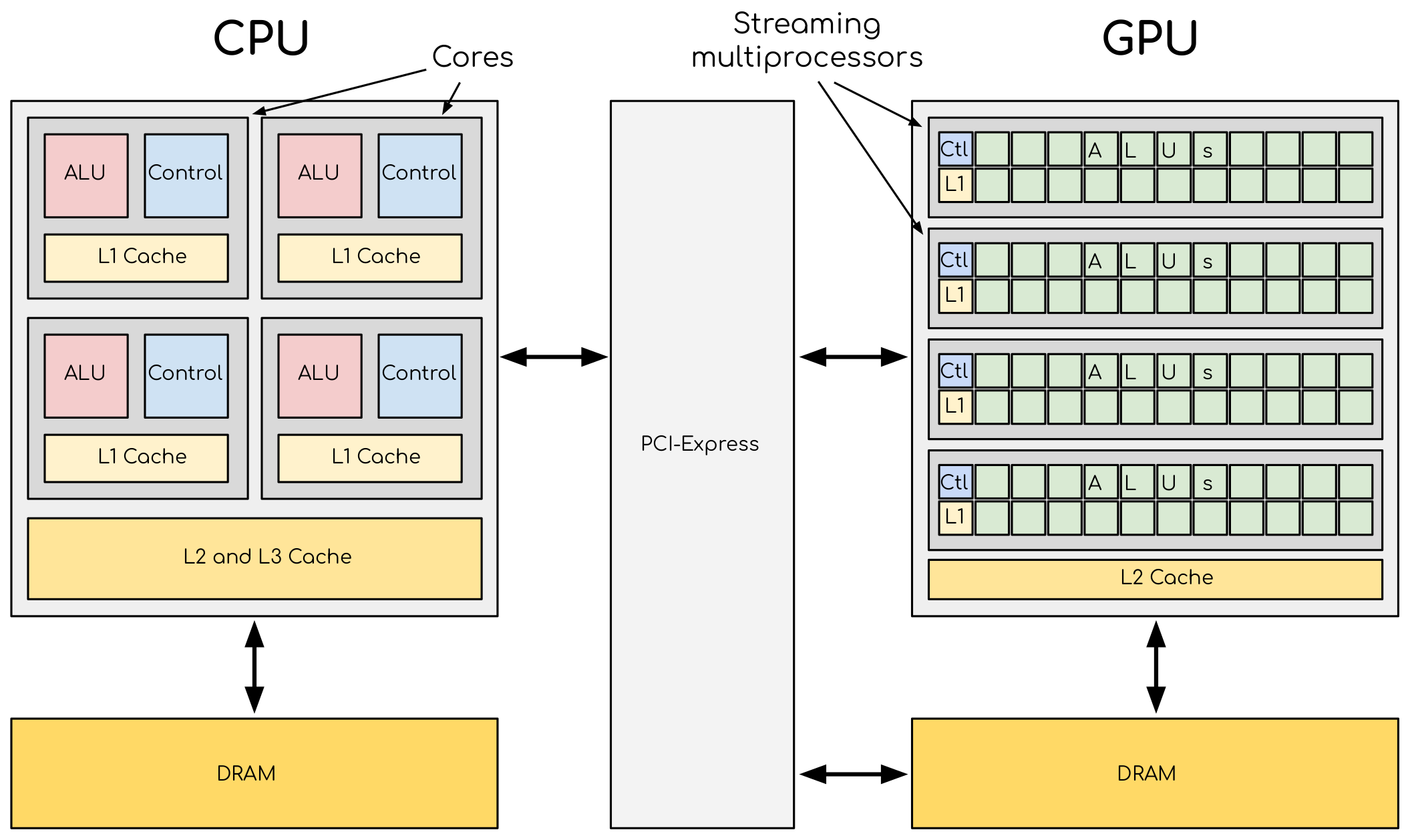
A comparison of the CPU and GPU architecture. CPU (left) has complex core structure and pack several cores on a single chip. GPU cores are very simple in comparison, they also share data and control between each other. This allows to pack more cores on a single chip, thus achieving very high compute density.
In short
Accelerators offer high performance due to their scalability and high density of compute elements.
They have separate circuit boards connected to CPUs via PCIe bus, with their own memory.
CPUs copy data from their own memory to the GPU memory, execute the program, and copy the results back.
GPUs run thousands of threads simultaneously, quickly switching between them to hide memory operations.
Effective data management and access pattern is critical on the GPU to avoid running out of memory.
Accelerators are a separate main circuit board with the processor, memory, power management, etc. It is connected to the motherboard with CPUs via PCIe bus. Having its own memory means that the data has to be copied to and from it (not neceseraly true anymore). CPU acts as a main processor, controlling the execution workflow. It copies the data from its own memory to the GPU memory, executes the program and copies the results back. GPUs runs tens of thousands of threads simultaneously on thousands of cores and does not do much of the data management. With many cores trying to access the memory simultaneously and with little cache available, the accelerator can run out of memory very quickly. This makes the data management and its access pattern is essential on the GPU. Accelerators like to be overloaded with the number of threads, because they can switch between threads very quickly. This allows to hide the memory operations: while some threads wait, others can compute.
A very important feature of the accelerators is their scalability. Computational cores on accelerators are usually grouped into multiprocessors. The multiprocessors share the data and logical elements. This allows to achieve a very high density of compute elements on a GPU. This also allows the scaling: more multiprocessors means more raw performance and this is very easy to achieve with more transistors available.
How do GPUs differ from CPUs?
CPUs and GPUs were designed with different goals in mind. While the CPU is designed to excel at executing a sequence of operations, called a thread, as fast as possible and can execute a few tens of these threads in parallel, the GPU is designed to excel at executing many thousands of them in parallel. GPUs were initially developed for highly-parallel task of graphic processing and therefore designed such that more transistors are devoted to data processing rather than data caching and flow control. More transistors dedicated to data processing is beneficial for highly parallel computations; the GPU can hide memory access latencies with computation, instead of relying on large data caches and complex flow control to avoid long memory access latencies, both of which are expensive in terms of transistors.
CPU |
GPU |
|---|---|
General purpose |
Highly specialized for parallelism |
Good for serial processing |
Good for parallel processing |
Great for task parallelism |
Great for data parallelism |
Low latency per thread |
High-throughput |
Large area dedicated cache and control |
Hundreds of floating-point execution units |
GPU platforms
GPUs come together with software stacks or APIs that work in conjunction with the hardware and give a standard way for the software to interact with the GPU hardware. They are used by software developers to write code that can take advantage of the parallel processing power of the GPU, and they provide a standard way for software to interact with the GPU hardware. Typically, they provide access to low-level functionality, such as memory management, data transfer between the CPU and the GPU, and the scheduling and execution of parallel processing tasks on the GPU. They may also provide higher level functions and libraries optimized for specific HPC workloads, like linear algebra or fast Fourier transforms. Finally, in order to facilitate the developers to optimize and write correct codes, debugging and profiling tools are also included.
NVIDIA, AMD, and Intel are the major companies which design and produces GPUs for HPC providing each its own suite CUDA, ROCm, and respectively oneAPI. This way they can offer optimization, differentiation (offering unique features tailored to their devices), vendor lock-in, licensing, and royalty fees, which can result in better performance, profitability, and customer loyalty. There are also cross-platform APIs such DirectCompute (only for Windows operating system), OpenCL, and SYCL.
CUDA - In short
- CUDA: NVIDIA’s parallel computing platform
Components: CUDA Toolkit & CUDA driver
Supports C, C++, and Fortran languages
- CUDA API Libraries: cuBLAS, cuFFT, cuRAND, cuSPARSE
Accelerate complex computations on GPUs
- Compilers: nvcc, nvc, nvc++, nvfortran
Support GPU and multicore CPU programming
Compatible with OpenACC and OpenMP
- Debugging tools: cuda-gdb, compute-sanitizer
Debug GPU and CPU code simultaneously
Identify memory access issues
- Performance analysis tools: NVIDIA Nsight Systems, NVIDIA Nsight Compute
Analyze system-wide and kernel-level performance
Optimize CPU and GPU usage, memory bandwidth, instruction throughput
Comprehensive CUDA ecosystem with extensive tools and features
ROCm - In short
- ROCm: Open software platform for AMD accelerators
Built for open portability across multiple vendors and architectures
Offers libraries, compilers, and development tools for AMD GPUs
Supports C, C++, and Fortran languages
Support GPU and multicore CPU programming
- Debugging:
roc-gdbcommand line tool Facilitates debugging of GPU programs
- Debugging:
- Performance analysis:
rocprofandroctracertools Analyze and optimize program performance
- Performance analysis:
Supports various heterogeneous programming models such as HIP, OpenMP, and OpenCL
- Heterogeneous-Computing Interface for Portability (HIP)
Enables source portability for NVIDIA and AMD platforms, Intel in plan
Provides
hipcccompiler driver and runtime libraries
- Libraries: Prefixed with
rocfor AMD platforms Can be called directly from HIP
hip-prefixed wrappers ensure portability with no performance cost
- Libraries: Prefixed with
oneAPI - In short
- Intel oneAPI: Unified software toolkit for optimizing and deploying applications across various architectures
Supports CPUs, GPUs, and FPGAs
Enables code reusability and performance portability
- Intel oneAPI Base Toolkit: Core set of tools and libraries for high-performance, data-centric applications
Includes C++ compiler with SYCL support
Features Collective Communications Library, Data Analytics Library, Deep Neural Networks Library, and more
- Additional toolkits: Intel oneAPI HPC Toolkit
Contains compilers, debugging tools, MPI library, and performance analysis tool
- Multiple programming models and languages supported:
OpenMP, Classic Fortran, C++, SYCL
Unless custom Intel libraries are used, the code is portable to other OpenMP and SYCL frameworks
- DPC++ Compiler: Supports Intel, NVIDIA, and AMD GPUs
Targets Intel GPUs using oneAPI Level Zero interface
Added support for NVIDIA GPUs with CUDA and AMD GPUs with ROCm
Debugging and performance analysis tools: Intel Adviser, Intel Vtune Profiler, Cluster Checker, Inspector, Intel Trace Analyzer and Collector, Intel Distribution for GDB
- Comprehensive and unified approach to heterogeneous computing
Abstracts complexities and provides consistent programming interface
Promotes code reusability, productivity, and performance portability
CUDA
Compute Unified Device Architecture is the parallel computing platform from NVIDIA. The CUDA API provides a comprehensive set of functions and tools for developing high-performance applications that run on NVIDIA GPUs. It consists of two main components: the CUDA Toolkit and the CUDA driver. The toolkit provides a set of libraries, compilers, and development tools for programming and optimizing CUDA applications, while the driver is responsible for communication between the host CPU and the device GPU. CUDA is designed to work with programming languages such as C, C++, and Fortran.
CUDA API provides many highly optimize libraries such as: cuBLAS (for linear algebra operations, such a dense matrix multiplication), cuFFT (for performing fast Fourier transforms), cuRAND (for generating pseudo-random numbers), cuSPARSE (for sparse matrices operations). Using these libraries, developers can quickly and easily accelerate complex computations on NVIDIA GPUs without having to write low-level GPU code themselves.
There are several compilers that can be used for developing and executing code on NVIDIA GPUs: nvcc. The latest versions are based on the widely used LLVM (low level virtual machine) open source compiler infrastructure. nvcc produces optimized code for NVIDIA GPUs and drives a supported host compiler for AMD, Intel, OpenPOWER, and Arm CPUs.
In addition to this are provided nvc (C11 compiler), nvc++ (C++17 compiler), and nvfortran (ISO Fortran 2003 compiler). These compilers can as well create code for execution on the NVIDIA GPUs, and also support GPU and multicore CPU programming with parallel language features, OpeanACC and OpenMP.
When programming mistakes are inevitable they have to be fixed as soon as possible. The CUDA toolkit includes the command line tool cuda-gdb which can be used to find errors in the code. It is an extension to GDB, the GNU Project debugger. The existing GDB debugging features are inherently present for debugging the host code, and additional features have been provided to support debugging CUDA device code, allowing simultaneous debugging of both GPU and CPU code within the same application. The tool provides developers with a mechanism for debugging CUDA applications running on actual hardware. This enables developers to debug applications without the potential variations introduced by simulation and emulation environments.
In addition to this the command line tool compute-sanitizer can be used to look exclusively for memory access problems: unallocated buffers, out of bounds accesses, race conditions, and uninitialized variables.
Finally, in order to utilize the GPUs at maximum some performance analysis tools. NVIDIA provides NVIDIA Nsight Systems and NVIDIA Nsight Compute tools for helping the developers to optimize their applications. The former, NVIDIA Nsight Systems, is a system-wide performance analysis tool that provides detailed metrics on both CPU and GPU usage, memory bandwidth, and other system-level metrics. The latter, NVIDIA Nsight Compute, is a kernel-level performance analysis tool that allows developers to analyze the performance of individual CUDA kernels. It provides detailed metrics on kernel execution, including memory usage, instruction throughput, and occupancy. These tools have graphical which can be used for all steps of the performance analysis, however on supercomputers it is recommended to use the command line interface for collecting the information needed and then visualize and analyse the results using the graphical interface on personal computers.
Apart from what was presented above there are many others tools and features provided by NVIDIA. The CUDA ecosystem is very well developed.
ROCm
ROCm is an open software platform allowing researchers to tap the power of AMD accelerators.
The ROCm platform is built on the foundation of open portability, supporting environments across multiple
accelerator vendors and architectures. In some way it is very similar to CUDA API.
It contains libraries, compilers, and development tools for programming and optimizing programs for AMD GPUs.
For debugging, it provides the command line tool rocgdb, while for performance analysis rocprof and roctracer.
In order to produce code for the AMD GPUs, one can use the Heterogeneous-Computing Interface for Portability (HIP).
HIP is a C++ runtime API and a set of tools that allows developers to write portable GPU-accelerated code for both NVIDIA and AMD platforms.
It provides the hipcc compiler driver, which will call the appropriate toolchain depending on the desired platform.
On the AMD ROCm platform, HIP provides a header and runtime library built on top of the HIP-Clang (ROCm compiler).
On an NVIDIA platform, HIP provides a header file which translates from the HIP runtime APIs to CUDA runtime APIs.
The header file contains mostly inlined functions and thus has very low overhead.
The code is then compiled with nvcc, the standard C++ compiler provided with CUDA.
On AMD platforms, libraries are prefixed by roc, which can be called directly from HIP. In order to make portable calls,
one can call the libraries using hip-prefixed wrappers. These wrappers can be used at no performance cost and ensure that
HIP code can be used on other platforms with no changes. Libraries included in the ROCm, are almost one-to-one equivalent to the ones supplied with CUDA.
ROCm also integrates with popular machine learning frameworks such as TensorFlow and PyTorch and provides optimized libraries and drivers to accelerate machine learning workloads on AMD GPUs enabling the researchers to leverage the power of ROCm and AMD accelerators to train and deploy machine learning models efficiently.
oneAPI
Intel oneAPI is a unified software toolkit developed by Intel that allows developers to optimize and deploy applications across a variety of architectures, including CPUs, GPUs, and FPGAs. It provides a comprehensive set of tools, libraries, and frameworks, enabling developers to leverage the full potential of heterogeneous computing environments. With oneAPI, the developers can write code once and deploy it across different hardware targets without the need for significant modifications or rewriting. This approach promotes code reusability, productivity, and performance portability, as it abstracts the complexities of heterogeneous computing and provides a consistent programming interface based on open standards.
The core of suite is Intel oneAPI Base Toolkit, a set of tools and libraries for developing high-performance, data-centric applications across diverse architectures. It features an industry-leading C++ compiler that implements SYCL, an evolution of C++ for heterogeneous computing. It includes the Collective Communications Library, the Data Analytics Library, the Deep Neural Networks Library, the DPC++/C++ Compiler, the DPC++ Library, the Math Kernel Library, the Threading Building Blocks, debugging tool Intel Distribution for GDB, performance analysis tools Intel Adviser and Intel Vtune Profiler, the Video Processing Library, Intel Distribution for Python, the DPC++ Compatibility Tool, the FPGA Add-on for oneAPI Base Toolkit, the Integrated Performance Primitives. This can be complemented with additional toolkits. The Intel oneAPI HPC Toolkit contains DPC++/C++ Compiler, Fortran and C++ Compiler Classic, debugging tools Cluster Checker and Inspector, Intel MPI Library, and performance analysis tool Intel Trace Analyzer and Collector.
oneAPI supports multiple programming models and programming languages. It enables developers to write OpenMP codes targeting multi-core CPUs and Intel GPUs using the Classic Fortran and C++ compilers and as well SYCL programs for GPUs and FPGAs using the DPC++ compiler. Initially, the DPC++ compiler only targeted Intel GPUs using the oneAPI Level Zero low-level programming interface, but now support for NVIDIA GPUs (using CUDA) and AMD GPUs (using ROCm) has been added. Overall, Intel oneAPI offers a comprehensive and unified approach to heterogeneous computing, empowering developers to optimize and deploy applications across different architectures with ease. By abstracting the complexities and providing a consistent programming interface, oneAPI promotes code reusability, productivity, and performance portability, making it an invaluable toolkit for developers in the era of diverse computing platforms.
Differences and similarities
GPUs in general support different features, even among the same producer. In general newer cards come with extra
features and sometimes old features are not supported anymore. It is important when compiling to create binaries
targeting the specific architecture when compiling. A binary built for a newer card will not run on older devices,
while a binary build for older devices might not run efficiently on newer architectures. In CUDA the compute
capability which is targeted is specified by the -arch=sm_XY, where X specifies the major architecture and it is between 1 and 9, and Y the minor. When using HIP on NVIDIA platforms one needs to use compiling option --gpu-architecture=sm_XY, while on AMD platforms --offload-arch=gfxabc ( where abc is the architecture code such as 90a for the MI200 series or 908 for MI100 series).
Note that in the case of portable (single source) programs one would specify openmp as well as target for
compilation, enabling to run the same code on multicore CPU.
Terminology
NVIDIA |
AMD |
Intel |
|---|---|---|
Streaming processor/streaming core |
SIMD lane |
Processing element |
SIMT unit |
SIMD unit |
Vector engine (XVE) |
Streaming Multiprocessor (SM) |
Computing Unit (CU) |
Xe-core / Execution unit (EU) |
GPU processing clusters (GPC) |
Compute Engine |
Xe-slice |
Please keep in mind, that this table is only a rough approximation. Each GPU architecture is different, and it’s impossible to make a 1-to-1 mapping between terms used by different vendors.
Summary
GPUs are designed to execute thousands of threads simultaneously, making them highly parallel processors. In contrast, CPUs excel at executing a smaller number of threads in parallel.
GPUs allocate a larger portion of transistors to data processing rather than data caching and flow control. This prioritization of data processing enables GPUs to effectively handle parallel computations and hide memory access latencies through computation.
GPU producers provide comprehensive toolkits, libraries, and compilers for developing high-performance applications that leverage the parallel processing power of GPUs. Examples include CUDA (NVIDIA), ROCm (AMD), and oneAPI (Intel).
These platforms offer debugging tools (e.g.,
cuda-gdb,rocgdb) and performance analysis tools (e.g., NVIDIA Nsight Systems, NVIDIA Nsight Compute,rocprof,roctracer) to facilitate code optimization and ensure efficient utilization of GPU resources.
Exercises
GPUs and memory
Which statement about the relationship between GPUs and memory is true?
GPUs are not affected by memory access latencies.
GPUs can run out of memory quickly with many cores trying to access the memory simultaneously.
GPUs have an unlimited cache size.
GPUs prefer to run with a minimal number of threads to manage memory effectively.
Solution
The correct answer is B). This is true because GPUs run many threads simultaneously on thousands of cores, and with limited cache available, this can lead to the GPU running out of memory quickly if many cores are trying to access the memory simultaneously. This is why data management and access patterns are essential in GPU computing.
Keypoints
GPUs vs. CPUs, key differences between them
GPU software suites, support specific GPU features, programming models, compatibility
Applications of GPUs