Directive-based models
Questions
What is OpenACC and OpenMP offloading
How to write GPU code using directives
Objectives
Understand the process of offloading
Understand the differences between OpenACC and OpenMP offloading
Understand the various levels of parallelism on a GPU
Understand what is data movement
Instructor note
30 min teaching
20 min exercises
The most common directive-based models for GPU parallel programming are OpenMP offloading and OpenACC. The parallelization is done by introducing directives in places which are targeted for parallelization.
OpenACC is known to be more descriptive, which means the programmer uses directives to tell the compiler how/where to parallelize the code and to move the data.
OpenMP offloading approach, on the other hand, is known to be more prescriptive, where the programmer uses directives to tell the compiler more explicitly how/where to parallelize the code, instead of letting the compiler decides.
In OpenMP/OpenACC the compiler directives are specified by using #pragma in C/C++ or as special comments identified by unique sentinels in Fortran. Compilers can ignore the directives if the support for OpenMP/OpenACC is not enabled.
The compiler directives are used for various purposes: for thread creation, workload distribution (work sharing), data-environment management, serializing sections of code or for synchronization of work among the threads.
Execution model
OpenMP and OpenACC use the fork-join model of parallel execution. The program begins as a single thread of execution, the master thread. Everything is executed sequentially until the first parallel region construct is encountered.
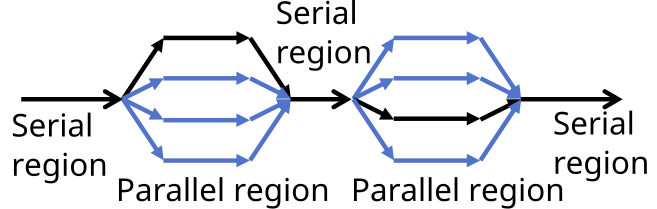
When a parallel region is encountered, master thread creates a group of threads, becomes the master of this group of threads, and is assigned the thread index 0 within the group. There is an implicit barrier at the end of the parallel regions.
Offloading Directives
OpenACC
In OpenACC, one of the most commonly used directives is kernels,
which defines a region to be transferred into a series of kernels to be executed in sequence on a GPU.
Work sharing is defined automatically for the separate kernels, but tuning prospects is limited.
Example: kernels
#include <stdio.h>
#include <openacc.h>
#define NX 102400
int main(void)
{
double vecA[NX], vecB[NX], vecC[NX];
int i;
/* Initialization of the vectors */
for (i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 2.0;
}
#pragma acc kernels
for (i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
return 0;
}
program main
implicit none
integer, parameter :: nx = 102400
integer :: i
double precision :: vecA(nx), vecB(nx), vecC(nx)
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$acc kernels
do i = 1, nx
vecC(i) = vecA(i) + vecB(i)
end do
!$acc end kernels
end program
The other approach of OpenACC to define parallel regions is to use parallel directive.
Contrary to the kernels directive, the parallel directive is more explicit and requires
more analysis by the programmer. Work sharing has to be defined manually using the loop directive,
and refined tuning is possible to achieve. The above example can be re-written as the following:
Example: parallel loop
#include <stdio.h>
#include <openacc.h>
#define NX 102400
int main(void)
{
double vecA[NX], vecB[NX], vecC[NX];
int i;
/* Initialization of the vectors */
for (i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 2.0;
}
#pragma acc parallel loop
for (i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
return 0;
}
program main
implicit none
integer, parameter :: nx = 102400
integer :: i
double precision :: vecA(nx), vecB(nx), vecC(nx)
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$acc parallel loop
do i = 1, nx
vecC(i) = vecA(i) + vecB(i)
end do
!$acc end parallel loop
end program
Sometimes we can obtain a little more performance by guiding the compiler to make specific choices. OpenACC has four levels of parallelism for offloading execution:
gang coarse grain: the iterations are distributed among the gangs
worker fine grain: worker’s threads are activated within gangs and iterations are shared among the threads
vector each worker activtes its threads working in SIMT fashion and the work is shared among the threads
seq the iterations are executed sequentially
Note
By default, gang, worker and vector parallelism are automatically decided and applied by the compiler.
The programmer could add clauses like num_gangs, num_workers and vector_length within the parallel region to specify the number of gangs, workers and vector length.
The optimal numbers are highly GPU architecture and compiler implementation dependent though.
There is no thread synchronization at gang level, which means there maybe a risk of race condition.
OpenMP Offloading
With OpenMP, the target directive is used for device offloading.
Example: target construct
#include <stdio.h>
#define NX 102400
int main(void)
{
double vecA[NX], vecB[NX], vecC[NX];
int i;
/* Initialization of the vectors */
for (i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 2.0;
}
#pragma omp target
for (i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
return 0;
}
program main
implicit none
integer, parameter :: nx = 102400
integer :: i
double precision :: vecA(nx), vecB(nx), vecC(nx)
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$omp target
do i = 1, nx
vecC(i) = vecA(i) + vecB(i)
end do
!$omp end target
end program
Compared to the OpenACC’s kernels directive, the target directive will not parallelise the underlying loop at all.
To achieve proper parallelisation, one needs to be more prescriptive and specify what one wants.
OpenMP offloading offers multiple levels of parallelism as well:
teams coarse grain: creates a league of teams and one master thread in each team, but no worksharing among the teams
distribute distributes the iterations across the master threads in the teams, but no worksharing among the threads within one team
parallel do/for fine grain: threads are activated within one team and worksharing among them
SIMD like the
vectordirective in OpenACC
Note
The programmer could add clauses like num_teams and thread_limit to specify the number of teams and threads within a team.
Threads in a team can synchronize but no synchronization among the teams.
Since OpenMP 5.0, there is a new loop directive available, which has the similar functionality as the corresponding one in OpenACC.
Keypoints
NVIDIA |
AMD |
Fortran OpenACC/OpenMP |
C/C++ OpenMP |
|---|---|---|---|
Threadblock |
Work group |
gang/teams |
teams |
Wrap |
Wavefront |
worker/simd |
parallel for simd |
Thread |
Work item |
vector/simd |
parallel for simd |
Exercise: Change the levels of parallelism
In this exercise we would like to change the levels of parallelism using clauses.
First compile and run one of the example to find out the default number of block and thread set by compiler at runtime.
To make a change, adding clauses like num_gangs, num_workers, vector_length for OpenACC
and num_teams, thread_limit for OpenMP offloading.
Remember to set the environment by executing export CRAY_ACC_DEBUG=2 at runtime.
How to compile and run the code interactively:
module load LUMI/23.03
module load partition/G
module load rocm/5.2.3
# OpenMP
cc -O2 -fopenmp -o ex1 ex1.c
# Only OpenACC Fortran is supported by HPE compiler.
salloc --nodes=1 --account=project_465000485 --partition=standard-g -t 2:00:00
srun --interactive --pty --jobid=<jobid> $SHELL
export CRAY_ACC_DEBUG=2
./ex1
module load LUMI/23.03
module load partition/G
module load rocm/5.2.3
# OpenMP
ftn -O2 -homp -o ex1 ex1.f90
# OpenACC
ftn -O2 -hacc -o ex1 ex1.f90
salloc --nodes=1 --account=project_465000485 --partition=standard-g -t 2:00:00
srun --interactive --pty --jobid=<jobid> $SHELL
export CRAY_ACC_DEBUG=2
./ex1
Example of a trivially parallelizable vector addition problem:
#include <stdio.h>
#include <math.h>
#define NX 102400
int main(void){
double vecA[NX],vecB[NX],vecC[NX];
/* Initialize vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
#pragma omp target teams distribute parallel for simd
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(nx) :: vecA,vecB,vecC
integer :: i
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$omp target teams distribute parallel do simd
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$omp end target teams distribute parallel do simd
end program vecsum
#include <stdio.h>
#include <openacc.h>
#define NX 102400
int main(void) {
double vecA[NX], vecB[NX], vecC[NX];
/* Initialization of the vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
#pragma acc parallel loop
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(:), allocatable :: vecA,vecB,vecC
integer :: i
allocate (vecA(nx), vecB(nx),vecC(nx))
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$acc parallel loop
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$acc end parallel loop
end program vecsum
Keypoints
Nvidia |
AMD |
Fortran OpenACC/OpenMP |
C/C++ OpenMP |
|---|---|---|---|
Threadblock |
Work group |
gang/teams |
teams |
Wrap |
Wavefront |
worker/simd |
parallel for simd |
Thread |
Work item |
vector/simd |
parallel for simd |
Each compiler supports different levels of parallelism
The size of gang/team/worker/vector_length can be chosen arbitrarily by the user but there are limits defined by the implementation.
The maximum thread/grid/block size can be found via
rocminfo/nvaccelinfo
Data Movement
Due to distinct memory spaces on host and device, transferring data becomes inevitable. New directives are needed to specify how variables are transferred from the host to the device data environment. The common transferred items consist of arrays (array sections), scalars, pointers, and structure elements. Various data clauses used for data movement is summarised in the following table
|
|
|
|
|
On entering the region, variables in the list are initialized on the device using the original values from the host |
|
|
At the end of the target region, the values from variables in the list are copied into the original variables on the host. On entering the region, the initial value of the variables on the device is not initialized |
|
|
The effect of both a map-to and a map-from |
|
|
On entering the region, data is allocated and uninitialized on the device |
|
|
Delete data on the device |
Note
- When mapping data arrays or pointers, be careful about the array section notation:
In C/C++: array[lower-bound:length]. The notation :N is equivalent to 0:N.
In Fortran:array[lower-bound:upper-bound]. The notation :N is equivalent to 1:N.
Data region
The specific data clause combined with the data directive constitutes the start of a data region. How the directives create storage, transfer data, and remove storage on the device are classified as two categories: structured data region and unstructured data region.
Structured Data Region
A structured data region is convenient for providing persistent data on the device which could be used for subsequent GPU directives.
Syntax for structured data region
#pragma omp target data [clauses]
{structured-block}
!$omp target data [clauses]
structured-block
!$omp end target data
#pragma acc data [clauses]
{structured-block}
!$acc data [clauses]
structured-block
!$acc end data
Unstructured Data Region
However it is inconvenient in real applications to use structured data region, therefore the unstructured data region with much more freedom in creating and deleting of data on the device at any appropriate point is adopted.
Syntax for unstructured data region
#pragma omp target enter data [clauses]
#pragma omp target exit data
!$omp target enter data [clauses]
!$omp target exit data
#pragma acc enter data [clauses]
#pragma acc exit data
!$acc enter data [clauses]
!$acc exit data
Keypoints
- Structured Data Region
Start and end points within a single subroutine
Memory exists within the data region
- Unstructured Data Region
Multiple start and end points across different subroutines
Memory exists until explicitly deallocated
Update
Sometimes, variables need to be synchronized between the host and the device memory, e.g. in order to write out variables on the host for debugging or visualization, and it is often used in conjunction with unstructured data regions. To control data transfer direction, a motion-clause must be present.
Syntax for update directive
#pragma omp target update [clauses]
motion-clause:
to (list)
from (list)
!$omp target update [clauses]
motion-clause:
to (list)
from (list)
#pragma acc update [clauses]
motion-clause:
self (list)
device (list)
!$acc update [clauses]
motion-clause:
self (list)
device (list)
Note
updatedirective can only be used in host code since data movement must be initiated from the host, i.e. it may not appear inside of a compute region.in OpenACC, motion-clause “host” has been deprecated and renamed “self”
Exercise: update
Trying to figure out the variable values on host and device at each check point.
#include <stdio.h>
int main(void)
{
int x = 0;
#pragma omp target data map(tofrom:x)
{
/* check point 1 */
x = 10;
/* check point 2 */
#pragma omp target update to(x)
/* check point 3 */
}
return 0;
}
program ex_update
implicit none
integer :: x
x = 0
!$acc data copy(x)
! check point 1
x = 10
! check point 2
!$acc update device(x)
! check point 3
!$acc end data
end program ex_update
Solution
check point |
x on host |
x on device |
|---|---|---|
check point1 |
0 |
0 |
check point2 |
10 |
0 |
check point3 |
10 |
10 |
Exercise: Adding data mapping clauses
Add proper data mapping clauses explicitly to the directives
#include <stdio.h>
#include <math.h>
#define NX 102400
int main(void){
double vecA[NX],vecB[NX],vecC[NX];
/* Initialize vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
/* Adding mapping clauses here */
#pragma omp target teams distribute parallel for simd
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
double sum = 0.0;
for (int i = 0; i < NX; i++) {
sum += vecC[i];
}
printf("The sum is: %8.6f \n", sum);
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(nx) :: vecA,vecB,vecC
real :: sum
integer :: i
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
! Adding mapping clauses here
!$omp target teams distribute parallel do simd
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$omp end target teams distribute parallel do simd
sum = 0.0
! Calculate the sum
do i = 1, nx
sum = vecC(i) + sum
end do
write(*,'(A,F18.6)') 'The sum is: ', sum
end program vecsum
#include <stdio.h>
#include <openacc.h>
#define NX 102400
int main(void) {
double vecA[NX], vecB[NX], vecC[NX];
/* Initialization of the vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
/* Adding mapping clauses here */
#pragma acc parallel loop
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
double sum = 0.0;
for (int i = 0; i < NX; i++) {
sum += vecC[i];
}
printf("The sum is: %8.6f \n", sum);
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(:), allocatable :: vecA,vecB,vecC
real :: sum
integer :: i
allocate (vecA(nx), vecB(nx),vecC(nx))
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
! Adding mapping clauses here
!$acc parallel loop
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$acc end parallel loop
sum = 0.0
! Calculate the sum
do i = 1, nx
sum = vecC(i) + sum
end do
write(*,'(A,F18.6)') 'The sum is: ', sum
end program vecsum
Solution
#include <stdio.h>
#include <math.h>
#define NX 102400
int main(void){
double vecA[NX],vecB[NX],vecC[NX];
/* Initialize vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
#pragma omp target teams distribute parallel for simd map(to:vecA[0:NX],vecB[0:NX]) map(from:vecC[0:NX])
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
double sum = 0.0;
for (int i = 0; i < NX; i++) {
sum += vecC[i];
}
printf("The sum is: %8.6f \n", sum);
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(nx) :: vecA,vecB,vecC
real :: sum
integer :: i
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$omp target teams distribute parallel do simd map(to:vecA,vecB) map(from:vecC)
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$omp end target teams distribute parallel do simd
sum = 0.0
! Calculate the sum
do i = 1, nx
sum = vecC(i) + sum
end do
write(*,'(A,F18.6)') 'The sum is: ', sum
end program vecsum
#include <stdio.h>
#include <openacc.h>
#define NX 102400
int main(void) {
double vecA[NX], vecB[NX], vecC[NX];
/* Initialization of the vectors */
for (int i = 0; i < NX; i++) {
vecA[i] = 1.0;
vecB[i] = 1.0;
}
#pragma acc parallel loop copyin(vecA[0:NX],vecB[0:NX]) copyout(vecC[0:NX])
{
for (int i = 0; i < NX; i++) {
vecC[i] = vecA[i] + vecB[i];
}
}
double sum = 0.0;
for (int i = 0; i < NX; i++) {
sum += vecC[i];
}
printf("The sum is: %8.6f \n", sum);
}
program vecsum
implicit none
integer, parameter :: nx = 102400
real, dimension(nx) :: vecA,vecB,vecC
real :: sum
integer :: i
! Initialization of vectors
do i = 1, nx
vecA(i) = 1.0
vecB(i) = 1.0
end do
!$acc parallel loop copyin(vecA,vecB) copyout(vecC)
do i=1,nx
vecC(i) = vecA(i) + vecB(i)
enddo
!$acc end parallel loop
sum = 0.0
! Calculate the sum
do i = 1, nx
sum = vecC(i) + sum
end do
write(*,'(A,F18.6)') 'The sum is: ', sum
end program vecsum
Optimize Data Transfers
Explicitly transfer the data as much as possible
Reduce the amount of data mapping between host and device, get rid of unnecessary data transfer
Try to keep data environment residing on the device as long as possible
Pros of directive-based frameworks
Incremental programming
Porting of existing software requires less work
Same code can be compiled to CPU and GPU versions easily using compiler flag
Low learning curve, do not need to know low-level hardware details
Good portability
See also
Keypoints
OpenACC and OpenMP-offloading enables you to annotate your code with special directives to identify areas to be executed in parallel on a GPU.
This saves time compared to lower-level approaches, but you need to be mindful of memory movement.