Data management with buffers and accessors
Questions
What facilities does SYCL offer to manage memory spaces in an heterogeneous environment?
Objectives
Learn about the buffer and accessor API.
Learn how the SYCL runtime manages memory.
Heterogeneous computing architectures offer a lot of computational power, but harnessing it can be highly nontrivial. The existence of multiple memory regions and hierarchies is one of the reasons for this.
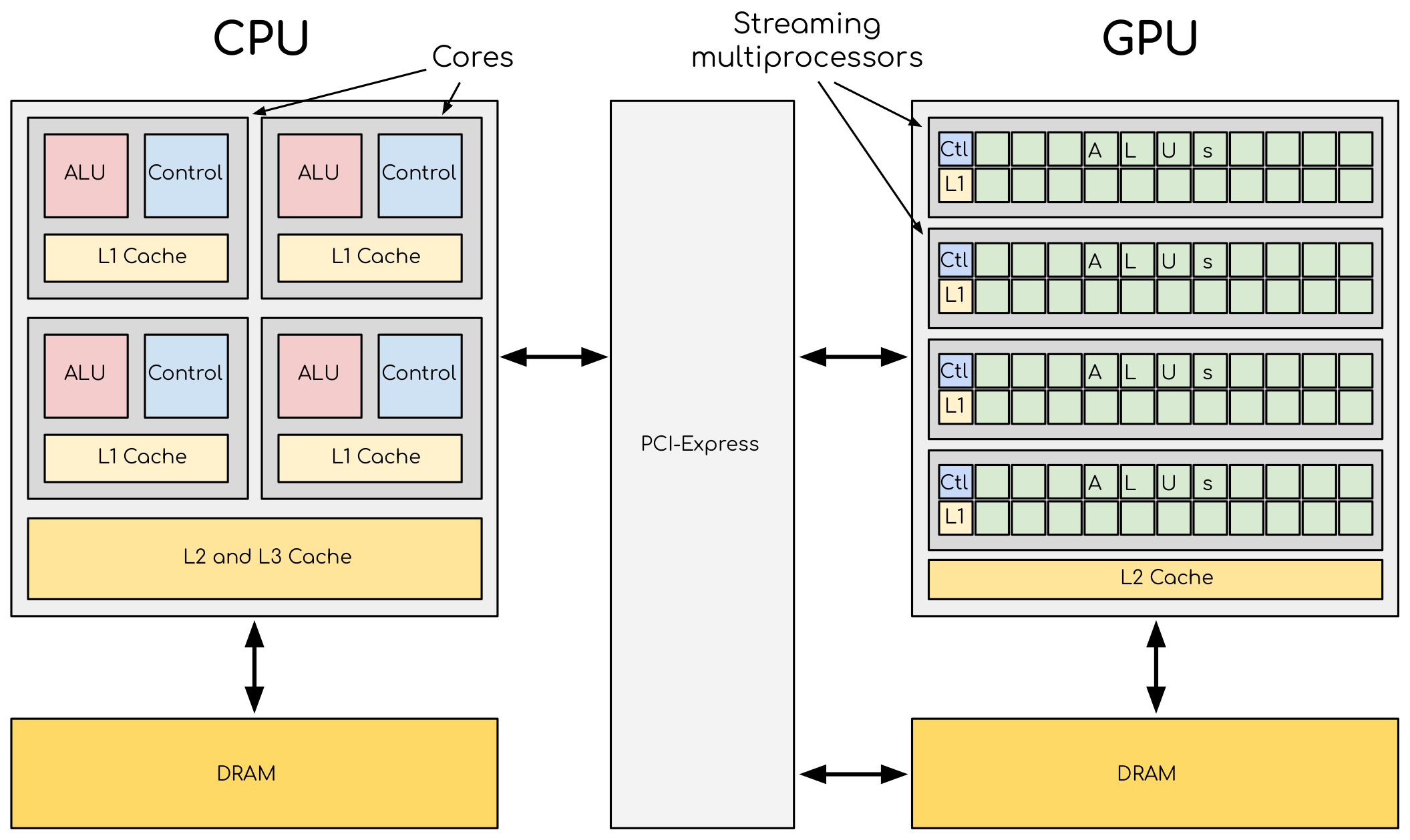
A comparison of CPU and GPU architectures. CPU (left) has complex core structure and pack several cores on a single chip. GPU (right) cores are very simple in comparison, they also share data and control between each other. This allows to pack more cores on a single chip, thus achieving very high compute density. [*] Global memory, GPU memory, CPU, and GPU caches have to be managed, more or less explicitly, by the programmer to achieve optimal performance.
Any meaningful computation requires data in input and will produce some data as output. There needs to be transfer of data to and from the compute units and migration of data has an impact on performance. SYCL gives us the freedom to decide whether to perform data movements explicitly or implicitly. The latter strategy delegates the problem to the runtime: it reduces the opportunity for data-movement related bugs, but leaves no room for hand-optimization. With the former, we retain full control, but we will have to write tedious and error-prone code for data transfer.
There are three memory-management abstractions in the SYCL standard:
unified shared memory. This is a pointer-based approach, familiar to C/C++ programmers and similar to CUDA/HIP low-level languages for accelerators. USM pointers on the host are valid pointers also on the device. This is at variance with “classic” pointers in CUDA/HIP. USM needs device support for a unified virtual address space.
the buffer and accessor API. A buffer is a handle to a 1-, 2-, or 3-dimensional memory location. It specifies where the memory location and where it can be accessed: host, device or both. As such, the buffer does not own the memory: it’s only a constrained view into it. We don’t work on buffer directly, but rather use accessors into them. This is analogous to a RAII-like approach, similar to what the STL does in C++.
images. They offer a similar API to buffer types, with extra functionality tailored for image processing. We will not discuss images in this workshop.
In this episode, we will look at the buffer and accessor API, while the next episode Data management with unified shared memory will discuss of USM. We will compare the two methods in Buffer-accessor model vs unified shared memory.
Buffers and memory allocation
Buffers are views into already allocated memory: a data abstraction the runtime uses to represent objects of given C++ types. The view is onto a 1-, 2-, or 3-dimensional array of data. The fact that buffers do not own their memory has two consequences for their usage:
We do not allocate buffers, but rather initialize them from already existing objects. Only trivially copyable C++ objects can be represented in a buffer: the runtime needs to be able to take byte-by-byte copies.
We do not access buffers directly, e.g. with a subscript operator or getters/setters. Rather we use accessor objects.
We construct buffers by specifying their size and what memory they should
provide a view for. The buffer class is templated over the type of the
underlying memory and its dimensionality (1, 2, or 3). We give the size as an
object of range type: ranges are also used to express parallelism, but we
postpone giving those details until episodes Expressing parallelism with SYCL: basic data-parallel kernels
and Expressing parallelism with SYCL: nd-range data-parallel kernels.
Some buffer constructors
We can construct a
bufferusing just arange. Data must be initialized in some other fashion:buffer(const range<dimensions> &bufferRange, const property_list &propList={});
We can set the data at construction passing a host pointer and a
range:buffer(T *hostData, const range<dimensions> &bufferRange, const property_list &propList={});
We can also pass a
std::shared_ptrand arange:buffer(const std::shared_ptr<T> &hostData, const range<dimensions> &bufferRange, const property_list &propList={});
For a one-dimensional
buffer, a pair of iterators can suffice:template <typename InputIterator> buffer(InputIterator first, InputIterator last, const property_list &propList={});
It is worth mentioning that buffer destructors are blocking. Thus, in
RAII fashion, defining SYCL work within a {} block (a new scope)
will ensure that buffers are updated after their data is accessed in a kernel!
Warning
When using a host pointer, we are promising the runtime that we will not touch the memory during the lifetime of the buffer. It is the programmer’s responsibility to keep that promise!
Creation of buffers is just one side of the coin. The buffer is only a view into memory and no migration of data occurs when we construct one and we cannot manipulate the underlying data of a buffer directly: both goals are achieved with accessors.
Buffers, accessors, and data movement
A buffer object “tells” the runtime how the data is laid out, while
accessor objects “tell” it how we are going to read from and write to
the underlying memory. This information is crucial for the runtime to correctly
schedule tasks and their execution. When you define accessors, you are defining
the data dependencies providing edges between the nodes in the task graph.
Accessor objects are templated over five parameters:
the type and the dimension, which will be the same as for the underlying buffer.
the access mode: how do we intend to access the data in the buffer? The possible values are
read,write, andread_writefor read-only (default forconstdata types), for write-only, and for read-write (default for non-constdata types) access, respectively.the access target: what memory and where do we intend to access? The default is
global_memorystating that the data resides in the device global memory space.the placeholder status: is this accessor a placeholder or not? We will not look at this parameter in detail. [†]
Device accessors can be created within a command group, for example:
buffer<double> A{range{42}};
Q.submit([&](handler &cgh){
accessor aA{A, cgh};
});
you can notice that CTAD and default template parameters help out here
and avoid us the tedious task of specifying all template parameters. The
accessor aA is in read_write mode, with target global_memory.
The SYCL standard provides convenient access tags to specify both access mode and target upon construction.
Tag value |
Access mode |
Access target |
|---|---|---|
|
|
default |
|
|
default |
|
|
default |
This avoids having to give the template arguments explicitly and saves quite a bit of typing!
buffer<double> A{range{42}};
Q.submit([&](handler &cgh){
auto aAA = accessor(A, cgh, write_only, no_init);
});
The no_init property tells the runtime to discard whatever previous contents
of the underlying buffer, which can lead to fewer data movements.
Finally, we use objects of type host_accessor to read data on the host from
a buffer previously accessed on a device:
buffer<double> A{range{42}};
Q.submit([&](handler &cgh){
accessor aA{A, cgh};
// fill buffer
cgh.parallel_for(range{42}, [=](id<1> & idx){
aA[idx] = 42.0;
})
});
host_accessor result{A};
for (int i = 0; i < N; i++) {
assert(result[i] == N);
}
These objects are similar to device accessors, but you will note that they are
constructed with just a buffer as argument. Further, we inspect the
contents of the buffer directly, even though we didn’t put buffer and queue
submission in a separate scope, nor did we wait on the queue.
The constructor for the host_accessor implicitly waits for the data to be
available.
None of the examples above invoked functions for memory movement between host and device: the buffer and accessor API completely relieves us from this burdensome aspect of heterogeneous programming.
AXPY with SYCL buffers and accessors
We will now write an AXPY implementation in SYCL, using the buffer and accessor API. Given a scalar, \(\alpha\), and two vectors, \(x\) and \(y\) , AXPY performs the following operation:
This will be a generic implementation: it will work with any arithmetic type, thanks to C++ templates.
Don’t do this at home, use optimized BLAS!
You can find a scaffold for the code in the
content/code/day-1/05_axpy-buf_acc/axpy.cpp file, alongside the CMake script
to build the executable. You will have to complete the source code to compile
and run correctly: follow the hints in the source file.
The code fills two std::vector objects and passes them to the axpy
function, which accepts a queue object as first parameter.
You have to complete this function:
Define buffers to view into the input and output vectors.
Schedule work on the
queueusing a command group.Define accessors to the input and output vectors, with proper access mode and target.
Write the AXPY kernel as a lambda function.
Return the computed value.
A working solution is in the solution subfolder.
Keypoints
Buffers and accessors delegate memory management issues to the SYCL runtime.
SYCL lets you abstract away the intricacies of host-device data dependencies.
It can be hard to adapt an existing code to the buffer-accessor model.
There might be performance overhead when adopting the buffer-accessor model.
Footnotes