Parallel Computing
Questions
What is the Global Interpreter Lock in Python?
How can Python code be parallelised?
Objectives
Become familiar with different types of parallelism
Learn the basics of parallel workflows, multiprocessing and distributed memory parallelism
Instructor note
40 min teaching/type-along
40 min exercises
The performance of a single CPU core has stagnated over the last ten years and most of the speed-up in modern CPUs is coming from using multiple CPU cores, i.e. parallel processing. Parallel processing is normally based either on multiple threads or multiple processes:
Shared memory parallelism (multithreading):
Parallel threads do separate work and communicate via the same memory and write to shared variables.
Multiple threads in a single Python program cannot execute at the same time (see global interpreter lock below)
Running multiple threads in Python is only effective for certain I/O-bound tasks
External libraries in other languages (e.g. C) which are called from Python can still use multithreading
Distributed memory parallelism (multiprocessing): Different processes manage their own memory segments and share data by communicating (e.g. passing messages using Message Passing Interface) as needed.
A process can contain one or more threads
Two processes can run on different CPU cores and different computers
Processes have more overhead than threads (creating and destroying processes takes more time)
Running multiple processes is only effective for compute-bound tasks
Note
“Embarrassingly” parallel: If you can run multiple instances of a program and do not need to synchronize/communicate with other instances, i.e. the problem at hand can be easily decomposed into independent tasks or datasets and there is no need to control access to shared resources, it is known as an embarrassingly parallel program. A few examples are listed here:
Monte Carlo analysis
Ensemble calculations of numerical weather prediction
Discrete Fourier transform
Convolutional neural networks
Applying same model on multiple datasets
GPU computing: This framwork takes advantages of the massively parallel compute units available in modern GPUs. It is ideal when you need a large number of simple arithmetic operations
Distributed computing (Spark, Dask): Master-worker parallelism. Master builds a graph of task dependencies and schedules to execute tasks in the appropriate order. In the next episode we will look at Dask, an array model extension and task scheduler, which combines multiprocessing with (embarrassingly) parallel workflows and “lazy” execution.
In the Python world, it is common to see the word concurrency denoting any type of simultaneous processing, including threads, tasks and processes.
Concurrent tasks can be executed in any order but with the same final results
Concurrent tasks can be but need not to be executed in parallel
concurrent.futuresmodule provides implementation of thread and process-based executors for managing resources pools for running concurrent tasksConcurrency is difficult: Race condition and Deadlock may arise in concurrent programs
Warning
Parallel programming requires that we adopt a different mental model compared to serial programming. Many things can go wrong and one can get unexpected results or difficult-to-debug problems. It is important to understand the possible pitfalls before embarking on code parallelisation. For an entertaining take on this, see Raymond Hettinger’s PyCon2016 presentation.
The Global Interpreter Lock (GIL)
The designers of the Python language made the choice that only one thread in a process can run actual Python code by using the so-called global interpreter lock (GIL). This means that approaches that may work in other languages (C, C++, Fortran), may not work in Python without being a bit careful. The reason GIL is needed is because part of the Python implementation related to the memory management is not thread-safe. At first glance, this is bad for parallelism. But one can avoid GIL through the folowing:
External libraries (NumPy, SciPy, Pandas, etc), written in C or other languages, can release the lock and run multi-threaded.
Most input/output tasks release the GIL.
There are several Python libraries that side-step the GIL, e.g. by using multiprocessing instead of threading.
Multithreading
Due to the GIL only one thread can execute Python code at once, and this makes threading rather useless for compute-bound problems in pure Python. However, multithreading is still relevant in two situations:
External libraries written in non-Python languages can take advantage of multithreading
Multithreading can be useful for running multiple I/O-bound tasks simultaneously.
Multithreaded libraries
NumPy and SciPy are built on external libraries such as LAPACK, FFTW, BLAS, which provide optimized routines for linear algebra, Fourier transforms etc. These libraries are written in C, C++ or Fortran and are thus not limited by the GIL, so they typically support actual multihreading during the execution. It might be a good idea to use multiple threads during calculations like matrix operations or frequency analysis.
Depending on the configuration, NumPy will often use multiple threads by default,
and one can use the environment variable OMP_NUM_THREADS to set the number
of threads manually by executing the following command in a terminal:
$ export OMP_NUM_THREADS=<N>
After setting this environment variable we continue as usual and multithreading will be turned on.
Multithreaded I/O
This is how an I/O-bound application might look:
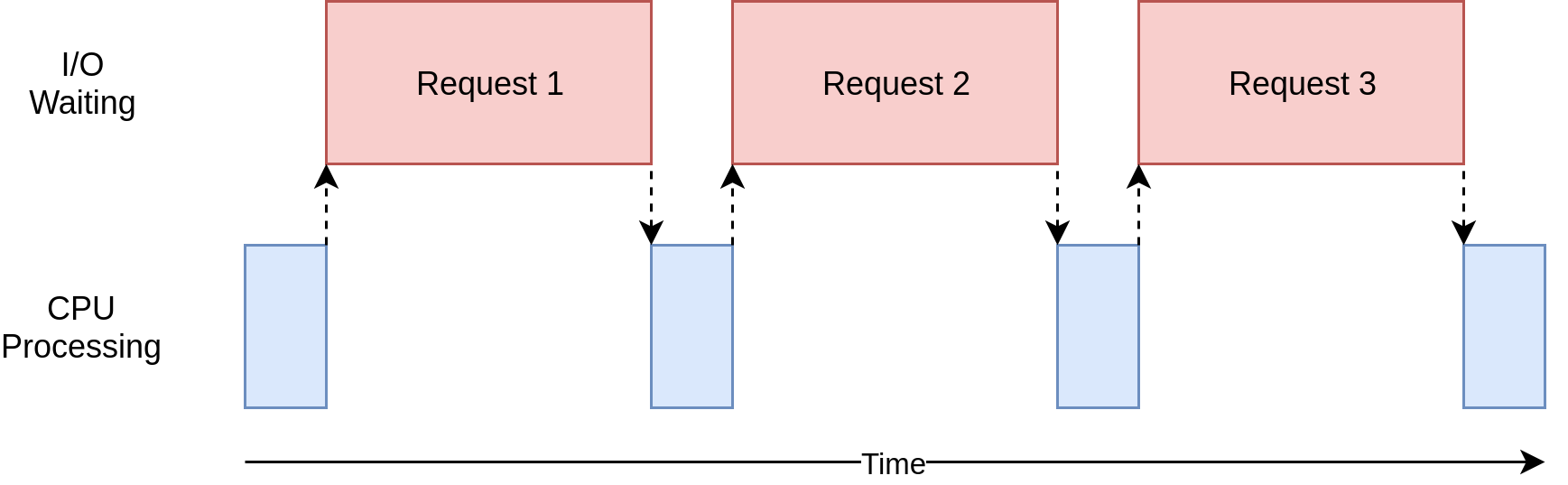
From https://realpython.com/, distributed via a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported licence
The threading library
provides an API for creating and working with threads. The simplest approach to
create and manage threads is to use the ThreadPoolExecutor class from concurrent.futures module.
An example use case could be to download data from multiple websites using
multiple threads:
import concurrent.futures
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=4) as executor:
executor.map(my_download_function, sites)
The speedup gained from multithreading I/O bound problems can be understood from the following image.
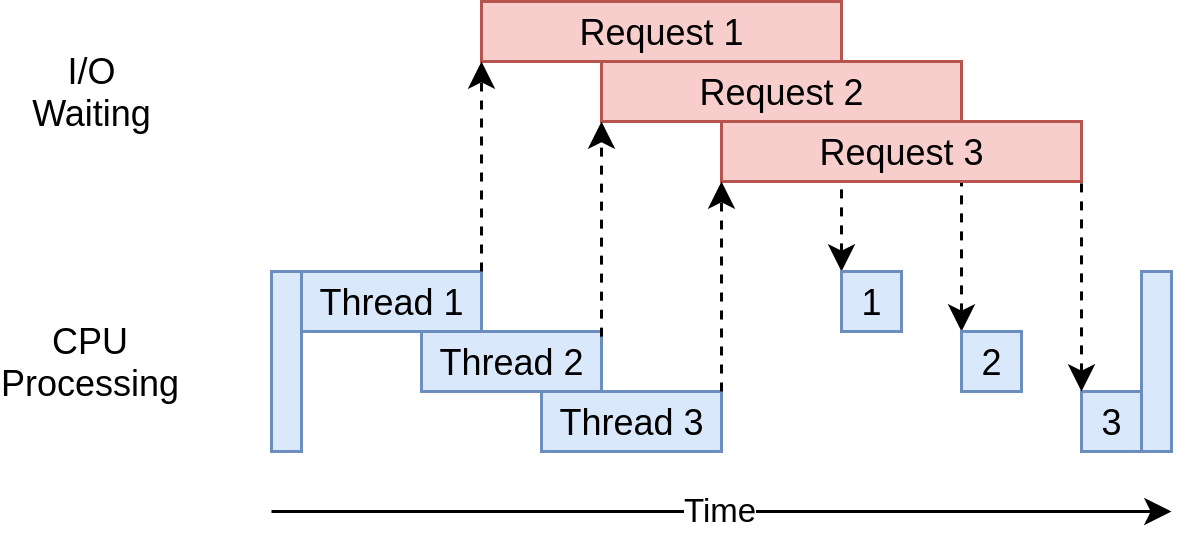
From https://realpython.com/, distributed via a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported licence
Further details on threading in Python can be found in the See also section below.
Multiprocessing
The multiprocessing module in Python supports spawning processes using an API
similar to the threading module. It effectively side-steps the GIL by using
subprocesses instead of threads, where each subprocess is an independent Python
process. One of the simplest ways to use multiprocessing is via Pool objects and
the parallel Pool.map() function, similarly to what we saw for multithreading above.
Note
concurrent.futures.ProcessPoolExecutor is actually a wrapper for
multiprocessing.Pool to unify the threading and process interfaces.
Multiple arguments
For functions that take multiple arguments one can instead use the Pool.starmap()
function, and there are other options as well, see below:
import multiprocessing as mp
def power_n(x, n):
return x ** n
if __name__ == '__main__':
with mp.Pool(processes=4) as pool:
res = pool.starmap(power_n, [(x, 2) for x in range(20)])
print(res)
from concurrent.futures import ProcessPoolExecutor
def power_n(x, n):
return x ** n
def f_(args):
return power_n(*args)
xs = np.arange(10)
chunks = np.array_split(xs, xs.shape[0]//2)
with ProcessPoolExecutor(max_workers=4) as pool:
res = pool.map(f_, chunks)
print(list(res))
from concurrent.futures import ProcessPoolExecutor
def power_n(x, n):
return x ** n
with ProcessPoolExecutor(max_workers=4) as pool:
res = pool.map(power_n, range(0,10,2), range(1,11,2))
print(list(res))
Interactive environments
Functionality within multiprocessing requires that the __main__ module be
importable by children processes. This means that some functions may not work
in the interactive interpreter like Jupyter-notebook.
multiprocessing has a number of other methods which can be useful for certain
use cases, including Process and Queue which make it possible to have direct
control over individual processes. Refer to the See also section below for a list
of external resources that cover these methods.
At the end of this episode you can turn your attention back to the word-count problem
and practice using multiprocessing pools of processes.
MPI
The message passing interface (MPI) is a standard workhorse of parallel computing. Nearly
all major scientific HPC applications use MPI. Like multiprocessing, MPI belongs to the
distributed-memory paradigm.
The idea behind MPI is that:
Tasks have a rank and are numbered 0, 1, 2, 3, …
Each task manages its own memory
Each task can run multiple threads
Tasks communicate and share data by sending messages.
Many higher-level functions exist to distribute information to other tasks and gather information from other tasks.
mpi4py provides Python bindings for the Message Passing Interface (MPI) standard.
This is how a hello world MPI program looks like in Python:
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
print('Hello from process {} out of {}'.format(rank, size))
MPI.COMM_WORLDis the communicator - a group of processes that can talk to each otherGet_rankreturns the individual rank (0, 1, 2, …) for each task that calls itGet_sizereturns the total number of ranks.
To run this code with a specific number of processes we use the mpirun command which
comes with the MPI library:
$ mpirun -np 4 python hello.py
# Hello from process 1 out of 4
# Hello from process 0 out of 4
# Hello from process 2 out of 4
# Hello from process 3 out of 4
Point-to-point and collective communication
The MPI standard contains a lot of functionality,
but in principle one can get away with only point-to-point communication (MPI.COMM_WORLD.send and
MPI.COMM_WORLD.recv). However, collective communication can sometimes require less effort as you
will learn in an exercise below.
In any case, it is good to have a mental model of different communication patterns in MPI.
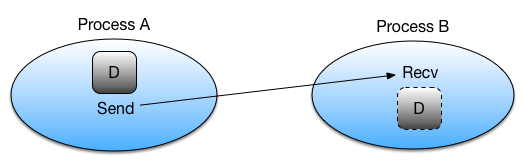
send and recv: blocking point-to-point communication between two ranks.
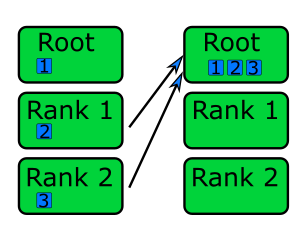
gather: all ranks send data to rank root.

scatter: data on rank 0 is split into chunks and sent to other ranks
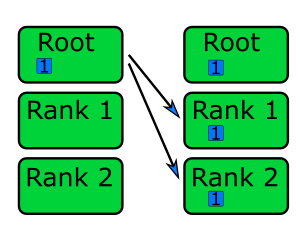
bcast: broadcast message to all ranks
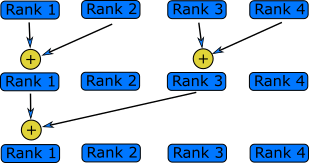
reduce: ranks send data which are reduced on rank root
Examples
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
n_ranks = comm.Get_size()
if rank != 0:
# All ranks other than 0 should send a message
message = "Hello World, I'm rank {:d}".format(rank)
comm.send(message, dest=0, tag=0)
else:
# Rank 0 will receive each message and print them
for sender in range(1, n_ranks):
message = comm.recv(source=sender, tag=0)
print(message)
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# Rank 0 will broadcast message to all other ranks
if rank == 0:
send_message = "Hello World from rank 0"
else:
send_message = None
receive_message = comm.bcast(send_message, root=0)
if rank != 0:
print(f"rank {rank} received message: {receive_message}")
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# Use gather to send all messages to rank 0
send_message = "Hello World, I'm rank {:d}".format(rank)
receive_message = comm.gather(send_message, root=0)
if rank == 0:
for i in range(n_ranks):
print(receive_message[i])
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
if rank == 0:
sendbuf = []
for i in range(size):
sendbuf.append(f"Hello World from rank 0 to rank {i}")
else:
sendbuf = None
recvbuf = comm.scatter(sendbuf, root=0)
print(f"rank {rank} received message: {recvbuf}")
In addition to the lower-case methods send(), recv(), broadcast() etc., there
are also upper-case methods Send(), Recv(), Broadcast(). These work with
buffer-like objects (including strings and NumPy arrays) which have known memory location and size.
Upper-case methods are faster and are strongly recommended for large numeric data.
Exercises
Multithreading NumPy
Here is a piece of code which does a symmetrical matrix inversion of size 4000 by 4000.
To run it, we can save it in a file named omp_test.py or download from here.
import numpy as np
import time
A = np.random.random((4000,4000))
A = A * A.T
time_start = time.time()
np.linalg.inv(A)
time_end = time.time()
print("time spent for inverting A is", round(time_end - time_start,2), 's')
Let us test it with 1 and 4 threads:
$ export OMP_NUM_THREADS=1
$ python omp_test.py
$ export OMP_NUM_THREADS=4
$ python omp_test.py
I/O-bound vs CPU-bound
In this exercise, we will simulate an I/O-bound process uing the sleep() function.
Typical I/O-bounded processes are disk accesses, network requests etc.
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from time import sleep
def func_io_bound(n):
sleep(n)
return
%%time
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(func_io_bound, [1,3,1,7])
%%time
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(func_io_bound, [1,3,1,7])
When the problem is compute intensive:
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import math
def func_cpu_bound(n):
sum = 0
for i in range(1, n+1):
sum += math.exp(math.log(math.sqrt(math.pow(i, 3.0))))
return sum
n=1000000
%%time
func_cpu_bound(n)
%%time
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(func_cpu_bound, [n,n,n,n])
%%time
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(func_cpu_bound, [n,n,n,n])
Race condition
Race condition is considered a common issue for multi-threading/processing applications,
which occurs when two or more threads attempt to access the shared data and
try to modify it at the same time. Try to run the example using different number n to see the differences.
Think about how we can solve this problem.
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from multiprocessing import Value
# define a function to increment the value by 1
def inc(i):
val.value += 1
# using a large number to see the problem
n = 100000
# create a shared data and initialize it to 0
val = Value('i', 0)
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(inc, range(n))
print(val.value)
# create a shared data and initialize it to 0
val = Value('i', 0)
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(inc, range(n))
print(val.value)
Solution
locking resources: explicitly using locks
duplicating resources: making copys of data to each threads/processes so that they do not need to share
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
from multiprocessing import Value, Lock
lock = Lock()
# adding lock
def inc(i):
lock.acquire()
val.value += 1
lock.release()
# define a large number
n = 100000
# create a shared data and initialize it to 0
val = Value('i', 0)
with ThreadPoolExecutor(max_workers=4) as pool:
pool.map(inc, range(n))
print(val.value)
# create a shared data and initialize it to 0
val = Value('i', 0)
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(inc, range(n))
print(val.value)
from concurrent.futures import ProcessPoolExecutor
from multiprocessing import Array
# define a function to increment the value by 1
def inc(i):
ind = mp.current_process().ident % 4
arr[ind] += 1
# define a large number
n = 100000
# create a shared data and initialize it to 0
arr = Array('i', [0]*4)
with ProcessPoolExecutor(max_workers=4) as pool:
pool.map(inc, range(n))
print(arr[:],sum(arr))
Compute numerical integrals
The primary objective of this exercise is to compute integrals \(\int_0^1 x^{3/2} \, dx\) numerically. One approach to integration is by establishing a grid along the x-axis. Specifically, the integration range is divided into ‘n’ segments or bins. Below is a basic serial code.
import math
import time
# Grid size
n = 100000000
def integration_serial(n):
h = 1.0 / float(n)
mysum = 0.0
for i in range(n):
x = h * (i + 0.5)
mysum += x ** (3/2)
return h * mysum
if __name__ == "__main__":
starttime = time.time()
integral = integration_serial(n)
endtime = time.time()
print("Integral value is %e, Error is %e" % (integral, abs(integral - 2/5))) # The correct integral value is 2/5
print("Time spent: %.2f sec" % (endtime-starttime))
# 13.63 sec
Think about how to parallelize the code using multithreading and multiprocessing.
Full source code
import math
import concurrent.futures
import time
# Grid size
n = 100000000
# Number of threads
numthreads = 4
def integration_concurrent(threadindex, n=n, numthreads=numthreads):
h = 1.0 / float(n)
mysum = 0.0
workload = n/numthreads
begin = int(workload*threadindex)
end = int(workload*(threadindex+1))
for i in range(begin, end):
x = h * (i + 0.5)
mysum += x ** (3/2)
return h * mysum
if __name__ == "__main__":
print(f"Using {numthreads} threads")
starttime = time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=numthreads) as executor:
partial_integrals = list(executor.map(integration_concurrent, range(numthreads)))
integral = sum(partial_integrals)
endtime = time.time()
print("Integral value is %e, Error is %e" % (integral, abs(integral - 2/5))) # The correct integral value is 2/5
print("Time spent: %.2f sec" % (endtime-starttime))
# 50.17 sec
import multiprocessing as mp
import math
import time
# Grid size
n = 100000000
nprocs = 4
def integration_process(pool_index, n, numprocesses):
h = 1.0 / float(n)
mysum = 0.0
workload = n / numprocesses
begin = int(workload * pool_index)
end = int(workload * (pool_index + 1))
for i in range(begin, end):
x = h * (i + 0.5)
mysum += x ** (3/2)
return h * mysum
if __name__ == '__main__':
print(f"Using {nprocs} processes")
starttime = time.time()
with mp.Pool(processes=nprocs) as pool:
partial_integrals = pool.starmap(integration_process, [(i, n, nprocs) for i in range(nprocs)])
integral = sum(partial_integrals)
endtime = time.time()
print("Integral value is %e, Error is %e" % (integral, abs(integral - 2/5))) # The correct integral value is 2/5
print("Time spent: %.2f sec" % (endtime - starttime))
# 3.53 sec
Word-autocorrelation example project
Inspired by a study of dynamic correlations of words in written text, we decide to investigate autocorrelations (ACFs) of words in our database of book texts in the word-count project. Many of the exercises below are based on working with the following word-autocorrelation code, so let us get familiar with it.
Full source code
import sys
import numpy as np
from wordcount import load_word_counts, load_text, DELIMITERS
import time
def preprocess_text(text):
"""
Remove delimiters, split lines into words and remove whitespaces,
and make lowercase. Return list of all words in the text.
"""
clean_text = []
for line in text:
for purge in DELIMITERS:
line = line.replace(purge, " ")
words = line.split()
for word in words:
word = word.lower().strip()
clean_text.append(word)
return clean_text
def word_acf(word, text, timesteps):
"""
Calculate word-autocorrelation function for given word
in a text. Each word in the text corresponds to one "timestep".
"""
acf = np.zeros((timesteps,))
mask = [w==word for w in text]
nwords_chosen = np.sum(mask)
nwords_total = len(text)
for t in range(timesteps):
for i in range(1,nwords_total-t):
acf[t] += mask[i]*mask[i+t]
acf[t] /= nwords_chosen
return acf
def ave_word_acf(words, text, timesteps=100):
"""
Calculate an average word-autocorrelation function
for a list of words in a text.
"""
acf = np.zeros((len(words), timesteps))
for n, word in enumerate(words):
acf[n, :] = word_acf(word, text, timesteps)
return np.average(acf, axis=0)
def setup(book, wc_book, nwords = 16):
# load book text and preprocess it
text = load_text(book)
clean_text = preprocess_text(text)
# load precomputed word counts and select top words
word_count = load_word_counts(wc_book)
top_words = [w[0] for w in word_count[:nwords]]
return clean_text, top_words
if __name__ == '__main__':
book = sys.argv[1]
wc_book = sys.argv[2]
filename = sys.argv[3]
nwords = 16
timesteps = 100
clean_text, top_words = setup(book, wc_book, nwords)
# compute average autocorrelation and time the execution
t0 = time.time()
acf_ave = ave_word_acf(top_words, clean_text, timesteps=100)
t1 = time.time()
print(f"serial time: {t1-t0}")
np.savetxt(filename, np.vstack((np.arange(1,101), acf_ave)).T, delimiter=',')
The script takes three command-line arguments: the path of a datafile (book text), the path to the processed word-count file, and the output filename for the computed autocorrelation function.
The
__main__block calls thesetup()function to preprocess the text (remove delimiters etc.) and load the pre-computed word-count results.word_acf()computes the word ACF in a text for a given word using simple for-loops (you will learn to speed it up later).ave_word_acf()loops over a list of words and computes their average ACF.
To run this code for one book e.g. pg99.txt:
$ git clone https://github.com/ENCCS/word-count-hpda.git
$ cd word-count-hpda
$ python source/wordcount.py data/pg99.txt processed_data/pg99.dat
$ python source/autocorrelation.py data/pg99.txt processed_data/pg99.dat results/acf_pg99.dat
It will print out the time it took to calculate the ACF.
Parallelize word-autocorrelation code with multiprocessing
A serial version of the code is available in the
source/autocorrelation.py
script in the word-count repository. The full script can be viewed above,
but we focus on the word_acf() and ave_word_acf() functions:
def word_acf(word, text, timesteps):
"""
Calculate word-autocorrelation function for given word
in a text. Each word in the text corresponds to one "timestep".
"""
acf = np.zeros((timesteps,))
mask = [w==word for w in text]
nwords_chosen = np.sum(mask)
nwords_total = len(text)
for t in range(timesteps):
for i in range(1,nwords_total-t):
acf[t] += mask[i]*mask[i+t]
acf[t] /= nwords_chosen
return acf
def ave_word_acf(words, text, timesteps=100):
"""
Calculate an average word-autocorrelation function
for a list of words in a text.
"""
acf = np.zeros((len(words), timesteps))
for n, word in enumerate(words):
acf[n, :] = word_acf(word, text, timesteps)
return np.average(acf, axis=0)
Think about what this code is doing and try to find a good place to parallelize it using a pool of processes.
With or without having a look at the hints below, try to parallelize the code using
multiprocessingand usetime.time()to measure the speedup when running it for one book.Note: You will not be able to use Jupyter for this task due to the above-mentioned limitation of
multiprocessing.
Hints
The most time-consuming parts of this code is the double-loop inside
word_acf() (you can confirm this in an exercise in the next episode).
This function is called 16 times in the ave_word_acf()
function, once for each word in the top-16 list. This looks like a perfect place to use a multiprocessing
pool of processes!
We would like to do something like:
with Pool(4) as p:
results = p.map(word_autocorr, words)
However, there’s an issue with this because word_acf() takes 3 arguments (word, text, timesteps).
We could solve this using the Pool.starmap() function:
with Pool(4) as p:
results = p.starmap(word_acf, [(i,j,k) for i,j,k in zip(words, 10*[text], 10*[timestep])]
But this might be somewhat inefficient because 10*[text] might take up quite a lot of memory.
One workaround is to use the partial method from functools which returns a new function with
partial application of the given arguments:
from functools import partial
word_acf_partial = partial(word_autocorr, text=text, timesteps=timesteps)
with Pool(4) as p:
results = p.map(word_acf_partial, words)
Solution
import sys
import numpy as np
from wordcount import load_word_counts, load_text, DELIMITERS
import time
from multiprocessing import Pool
from functools import partial
def preprocess_text(text):
"""
Remove delimiters, split lines into words and remove whitespaces,
and make lowercase. Return list of all words in the text.
"""
clean_text = []
for line in text:
for purge in DELIMITERS:
line = line.replace(purge, " ")
words = line.split()
for word in words:
word = word.lower().strip()
clean_text.append(word)
return clean_text
def word_acf(word, text, timesteps):
"""
Calculate word-autocorrelation function for given word
in a text. Each word in the text corresponds to one "timestep".
"""
acf = np.zeros((timesteps,))
mask = [w==word for w in text]
nwords_chosen = np.sum(mask)
nwords_total = len(text)
for t in range(timesteps):
for i in range(1,nwords_total-t):
acf[t] += mask[i]*mask[i+t]
acf[t] /= nwords_chosen
return acf
def ave_word_acf(words, text, timesteps=100):
"""
Calculate an average word-autocorrelation function
for a list of words in a text.
"""
acf = np.zeros((len(words), timesteps))
for n, word in enumerate(words):
acf[n, :] = word_acf(word, text, timesteps)
return np.average(acf, axis=0)
def ave_word_acf_pool(words, text, nproc=4, timesteps=100):
"""
Calculate an average word-autocorrelation function
for a list of words in a text using multiprocessing.
"""
word_acf_partial = partial(word_acf, text=text, timesteps=timesteps)
with Pool(nproc) as p:
results = p.map(word_acf_partial, words)
acf = np.array(results)
return np.average(acf, axis=0)
def setup(book, wc_book, nwords = 16):
# load book text and preprocess it
text = load_text(book)
clean_text = preprocess_text(text)
# load precomputed word counts and select top words
word_count = load_word_counts(wc_book)
top_words = [w[0] for w in word_count[:nwords]]
return clean_text, top_words
if __name__ == '__main__':
book = sys.argv[1]
wc_book = sys.argv[2]
filename = sys.argv[3]
nwords = 16
timesteps = 100
clean_text, top_words = setup(book, wc_book, nwords)
# compute average autocorrelation and time the execution
t0 = time.time()
acf_ave = ave_word_acf(top_words, clean_text, timesteps)
t1 = time.time()
nproc = 4
acf_pool_ave = ave_word_acf_pool(top_words, clean_text, nproc, timesteps)
t2 = time.time()
# assert that multiprocessing solution gives correct results
np.testing.assert_array_equal(acf_ave, acf_pool_ave)
print(f"serial time: {t1-t0}")
print(f"parallel map time: {t2-t1}")
np.savetxt(sys.argv[3], np.vstack((np.arange(1,101), acf_ave)).T, delimiter=',')
Write an MPI version of word-autocorrelation
Just like with multiprocessing, the most natural MPI solution parallelizes over
the words used to compute the word-autocorrelation.
For educational purposes, both point-to-point and collective communication
implementations will be demonstrated here.
Start by importing mpi4py (from mpi4py import MPI) at the top of the script.
Here is a new function which takes care of managing MPI tasks.
The problem needs to be split up between N ranks, and the method needs to be general
enough to handle cases where the number of words is not a multiple of the number of ranks.
Below we see a standard algorithm to accomplish this. The function also calls
two functions which implement point-to-point and collective communication, respectively, to collect
individual results to one rank which computes the average
def mpi_acf(book, wc_book, nwords = 16, timesteps = 100):
# initialize MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# load book text and preprocess it
clean_text, top_words = setup(book, wc_book, nwords)
# distribute words among MPI tasks
count = nwords // n_ranks
remainder = nwords % n_ranks
# first 'remainder' ranks get 'count + 1' tasks each
if rank < remainder:
first = rank * (count + 1)
last = first + count + 1
# remaining 'nwords - remainder' ranks get 'count' task each
else:
first = rank * count + remainder
last = first + count
# each rank gets unique words
my_words = top_words[first:last]
print(f"My rank number is {rank} and first, last = {first}, {last}")
# use collective function
acf_tot = ave_word_acf_gather(comm, my_words, clean_text, timesteps)
# use p2p function
#acf_tot = ave_word_acf_p2p(comm, my_words, clean_text, timesteps)
# only rank 0 has the averaged data
if rank == 0:
return acf_tot / nwords
What type of communication can we use?
The end result should be an average of all the word-autocorrelation functions. What type of communication can be used to collect the results on one rank which computes the average and prints it to file?
Study the two “faded” MPI function implementations below, one using point-to-point communication and the other using
collective communication. Try to figure out what you should replace the ____ with.
def ave_word_acf_p2p(comm, my_words, text, timesteps=100):
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# each rank computes its own set of acfs
my_acfs = np.zeros((len(____), timesteps))
for i, word in enumerate(my_words):
my_acfs[i,:] = word_acf(word, text, timesteps)
if ____ == ____:
results = []
# append own results
results.append(my_acfs)
# receive data from other ranks and append to results
for sender in range(1, ____):
results.append(comm.____(source=sender, tag=12))
# compute total
acf_tot = np.zeros((timesteps,))
for i in range(____):
for j in range(len(results[i])):
acf_tot += results[i][j]
return acf_tot
else:
# send data
comm.____(my_acfs, dest=____, tag=12)
def ave_word_acf_gather(comm, my_words, text, timesteps=100):
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# each rank computes its own set of acfs
my_acfs = np.zeros((len(____), timesteps))
for i, word in enumerate(my_words):
my_acfs[i,:] = word_acf(word, text, timesteps)
# gather results on rank 0
results = comm.____(____, root=0)
# loop over ranks and results. result is a list of lists of ACFs
if ____ == ____:
acf_tot = np.zeros((timesteps,))
for i in range(n_ranks):
for j in range(len(results[i])):
acf_tot += results[i][j]
return acf_tot
After implementing one or both of these functions, run your code and time the result for different number of tasks!
$ time mpirun -np <N> python source/autocorrelation.py data/pg58.txt processed_data/pg58.dat results/pg58_acf.csv
Solution
import sys
import numpy as np
from wordcount import load_word_counts, load_text, DELIMITERS
import time
from mpi4py import MPI
def preprocess_text(text):
"""
Remove delimiters, split lines into words and remove whitespaces,
and make lowercase. Return list of all words in the text.
"""
clean_text = []
for line in text:
for purge in DELIMITERS:
line = line.replace(purge, " ")
words = line.split()
for word in words:
word = word.lower().strip()
clean_text.append(word)
return clean_text
def word_acf(word, text, timesteps):
"""
Calculate word-autocorrelation function for given word
in a text. Each word in the text corresponds to one "timestep".
"""
acf = np.zeros((timesteps,))
mask = [w==word for w in text]
nwords_chosen = np.sum(mask)
nwords_total = len(text)
for t in range(timesteps):
for i in range(1,nwords_total-t):
acf[t] += mask[i]*mask[i+t]
acf[t] /= nwords_chosen
return acf
def ave_word_acf(words, text, timesteps=100):
"""
Calculate an average word-autocorrelation function
for a list of words in a text.
"""
acf = np.zeros((len(words), timesteps))
for n, word in enumerate(words):
acf[n, :] = word_acf(word, text, timesteps)
return np.average(acf, axis=0)
def ave_word_acf_p2p(comm, my_words, text, timesteps=100):
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# each rank computes its own set of acfs
my_acfs = np.zeros((len(my_words), timesteps))
for i, word in enumerate(my_words):
my_acfs[i,:] = word_acf(word, text, timesteps)
if rank == 0:
results = []
# append own results
results.append(my_acfs)
# receive data from other ranks and append to results
for sender in range(1, n_ranks):
results.append(comm.recv(source=sender, tag=12))
# compute total
acf_tot = np.zeros((timesteps,))
for i in range(n_ranks):
for j in range(len(results[i])):
acf_tot += results[i][j]
return acf_tot
else:
# send data
comm.send(my_acfs, dest=0, tag=12)
def ave_word_acf_gather(comm, my_words, text, timesteps=100):
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# each rank computes its own set of acfs
my_acfs = np.zeros((len(my_words), timesteps))
for i, word in enumerate(my_words):
my_acfs[i,:] = word_acf(word, text, timesteps)
# gather results on rank 0
results = comm.gather(my_acfs, root=0)
# loop over ranks and results. result is a list of lists of ACFs
if rank == 0:
acf_tot = np.zeros((timesteps,))
for i in range(n_ranks):
for j in range(len(results[i])):
acf_tot += results[i][j]
return acf_tot
def setup(book, wc_book, nwords = 16):
# load book text and preprocess it
text = load_text(book)
clean_text = preprocess_text(text)
# load precomputed word counts and select top words
word_count = load_word_counts(wc_book)
top_words = [w[0] for w in word_count[:nwords]]
return clean_text, top_words
def mpi_acf(book, wc_book, nwords = 16, timesteps = 100):
# initialize MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
n_ranks = comm.Get_size()
# load book text and preprocess it
clean_text, top_words = setup(book, wc_book, nwords)
# distribute words among MPI tasks
count = nwords // n_ranks
remainder = nwords % n_ranks
# first 'remainder' ranks get 'count + 1' tasks each
if rank < remainder:
first = rank * (count + 1)
last = first + count + 1
# remaining 'nwords - remainder' ranks get 'count' task each
else:
first = rank * count + remainder
last = first + count
# each rank gets unique words
my_words = top_words[first:last]
print(f"My rank number is {rank} and first, last = {first}, {last}")
# use collective function
acf_tot = ave_word_acf_gather(comm, my_words, clean_text, timesteps)
# use p2p function
#acf_tot = ave_word_acf_p2p(comm, my_words, clean_text, timesteps)
# only rank 0 has the averaged data
if rank == 0:
return acf_tot / nwords
if __name__ == '__main__':
# load book text and preprocess it
book = sys.argv[1]
wc_book = sys.argv[2]
filename = sys.argv[3]
acf = mpi_acf(book, wc_book, 16, 100)
rank = MPI.COMM_WORLD.Get_rank()
if rank == 0:
nsteps = len(acf)
output = np.vstack((np.arange(1,nsteps+1), acf)).T
np.savetxt(filename, output, delimiter=',')
See also
Parallel programming in Python with multiprocessing, part 1 and part 2
Parallel programming in Python with mpi4py, part 1 and part 2
Keypoints
Beaware of GIL and its impact on performance
Use threads for I/O-bound tasks and multiprocessing for compute-bound tasks
Make it right before trying to make it fast