Efficient Array Computing
Objectives
Understand limitations of Python’s standard library for large data processing
Understand the logic behind NumPy ndarrays and learn to use some NumPy numerical computing tools
Learn to use data structures and analysis tools from Pandas
Instructor note
30 min teaching/type-along
30 min exercises
This episode is partly based on material from this repository on HPC-Python from CSC and this Python for Scientific Computing lesson, distributed under MIT and CC-BY-4.0 licenses, respectively.
Why can Python be slow?
Computer programs are nowadays practically always written in a high-level human readable programming language and then translated to the actual machine instructions that a processor understands. There are two main approaches for this translation:
For compiled programming languages, the translation is done by a compiler before the execution of the program
For interpreted languages, the translation is done by an interpreter during the execution of the program
Compiled languages are typically more efficient, but the behaviour of the program during runtime is more static than with interpreted languages. The compilation step can also be time consuming, so the software cannot always be tested as rapidly during development as with interpreted languages.
Python is an interpreted language, and many features that make development rapid with Python are a result of that, with the price of reduced performance in many cases.
Dynamic typing
Python is a dynamic language. Variables get a type only during the runtime when values (Python objects) are assigned to them, so it is more difficult for the interpreter to optimize the execution. In comparison, a compiler can make extensive analysis and optimization before the execution. Even though there has in recent years been a lot of progress in just-in-time (JIT) compilation techniques that allow programs to be optimized at runtime, the inherent, dynamic nature of the Python programming language remains one of its main performance bottlenecks.
Flexible data structures
The built-in data structures of Python, such as lists and dictionaries, are very flexible, but they are also very generic which makes them not well suited for extensive numerical computations. Even though the implementation of data structures is often quite efficient when processing different types of data, there is a lot of overhead due to the generic nature of these data structures when processing only a single type of data.
In summary, the flexibility and dynamic nature of Python, which enhances programmer productivity greatly, is also the main cause for the performance problems. Fortunately, as we discuss in the course, many of the bottlenecks can be circumvented.
NumPy
As probably the most fundamental building block of the scientific computing ecosystem in Python, NumPy offers comprehensive mathematical functions, random number generators, linear algebra routines, Fourier transforms, and more.
NumPy is based on well-optimized C code, which gives much better performace than regular Python.
In particular, by using homogeneous
data structures, NumPy vectorizes mathematical operations where fast pre-compiled code
can be applied to a sequence of data instead of using traditional for loops.
Arrays
The core of NumPy is the NumPy ndarray (n-dimensional array). Compared to a Python list,
an ndarray is similar in terms of serving as a data container.
Some differences between the two are:
ndarrays can have multiple dimensions, e.g. a 1-D array is a vector, a 2-D array is a matrix
ndarrays are fast only when all data elements are of the same type
ndarray operations are fast when vectorized
ndarrays are slower for certain operations, e.g. appending elements

Data types
NumPy supports a much greater variety of numerical types (dtype) than Python does.
There are 5 basic numerical types representing booleans (bool), integers (int),
unsigned integers (uint) floating point (float) and complex (complex).
import numpy as np
# create float32 variable
x = np.float32(1.0)
# array with uint8 unsigned integers
z = np.arange(3, dtype=np.uint8)
# convert array to floats
z.astype(float)
Creating NumPy arrays
One way to create a NumPy array is to convert from a Python list, but make sure that the list is homogeneous
(contains same data type) otherwise performace will be downgraded.
Since appending elements to an existing array is slow, it is a common practice to preallocate the necessary space
with np.zeros or np.empty when converting from a Python list is not possible.
import numpy as np
a = np.array((1, 2, 3, 4), float)
a
# array([ 1., 2., 3., 4.])
list1 = [[1, 2, 3], [4, 5, 6]]
mat = np.array(list1, complex)
# create complex array, with imaginary part equal to zero
mat
# array([[ 1.+0.j, 2.+0.j, 3.+0.j],
# [ 4.+0.j, 5.+0.j, 6.+0.j]])
mat.shape
# (2, 3)
mat.size
# 6
arange and linspace can generate ranges of numbers:
a = np.arange(10)
a
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
b = np.arange(0.1, 0.2, 0.02)
b
# array([0.1 , 0.12, 0.14, 0.16, 0.18])
c = np.linspace(-4.5, 4.5, 5)
c
# array([-4.5 , -2.25, 0. , 2.25, 4.5 ])
Array with given shape initialized to zeros, ones, arbitrary value (full)
or unitialized (empty):
a = np.zeros((4, 6), float)
a.shape
# (4, 6)
b = np.ones((2, 4))
b
# array([[ 1., 1., 1., 1.],
# [ 1., 1., 1., 1.]])
c = np.full((2, 3), 4.2)
c
# array([[4.2, 4.2, 4.2],
# [4.2, 4.2, 4.2]])
d = np.empty((2, 2))
# array([[0.00000000e+000, 1.03103236e-259],
# [0.00000000e+000, 9.88131292e-324]])
Similar arrays as an existing array:
a = np.zeros((4, 6), float)
b = np.empty_like(a)
c = np.ones_like(a)
d = np.full_like(a, 9.1)
Array operations and manipulations
All the familiar arithmetic operators in NumPy are applied elementwise:
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
a + b

a/b

import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([10, 10, 10], [10, 10, 10]])
a + b # array([[11, 12, 13],
# [14, 15, 16]])

Array indexing
Basic indexing is similar to Python lists. Note that advanced indexing creates copies of arrays.
import numpy as np
data = np.array([1,2,3,4,5,6,7,8])

Integer indexing:

Fancy indexing:

Boolean indexing:

import numpy as np
data = np.array([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12]])

Integer indexing:

Fancy indexing:

Boolean indexing:

Array aggregation
Apart from aggregating values, one can also aggregate across rows or columns by using the axis parameter:
import numpy as np
data = np.array([[0, 1, 2], [3, 4, 5]])




Array reshaping
Sometimes, you need to change the dimension of an array. One of the most common need is to transposing the matrix during the dot product. Switching the dimensions of a NumPy array is also quite common in more advanced cases.
import numpy as np
data = np.array([1,2,3,4,5,6,7,8,9,10,11,12])

data.reshape(4,3)

data.reshape(3,4)

Views and copies of arrays
Simple assignment creates references to arrays
Slicing creates views to the arrays
Use
copyfor real copying of arrays
a = np.arange(10)
b = a # reference, changing values in b changes a
b = a.copy() # true copy
c = a[1:4] # view, changing c changes elements [1:4] of a
c = a[1:4].copy() # true copy of subarray
I/O with NumPy
Numpy provides functions for reading from/writing to files. Both ASCII and binary formats are supported with the CSV and npy/npz formats:
The numpy.loadtxt() and numpy.savetxt() functions can be used. They
save in a regular column layout and can deal with different delimiters,
column titles and numerical representations.
a = np.array([1, 2, 3, 4]) np.savetxt("my_array.csv", a) b = np.loadtxt("my_array.csv") a == b # True
The npy format is a binary format used to dump arrays of any
shape. Several arrays can be saved into a single npz file, which is
simply a zipped collection of different npy files. All the arrays to
be saved into a npz file can be passed as kwargs to the numpy.savez()
function. The data can then be recovered using the numpy.load() method,
which returns a dictionary-like object in which each key points to one of the arrays:
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
np.savez("my_arrays.npz", array_1=a, array_2=b)
data = np.load("my_arrays.npz")
data['array_1'] == a
data['array_2'] == b
# Both are true
Random numbers
The module
numpy.randomprovides several functions for constructing random arraysrandom(): uniform random numbersnormal(): normal distributionchoice(): random sample from given array…
import numpy.random as rnd
rnd.random((2,2))
# array([[ 0.02909142, 0.90848 ],
# [ 0.9471314 , 0.31424393]])
rnd.choice(numpy.arange(4), 10)
# array([0, 1, 1, 2, 1, 1, 2, 0, 2, 3])
Polynomials
Polynomial is defined by an array of coefficients p
p(x, N) = p[0] x^{N-1} + p[1] x^{N-2} + ... + p[N-1]For example:
Least square fitting:
numpy.polyfit()Evaluating polynomials:
numpy.polyval()Roots of polynomial:
numpy.roots()
x = np.linspace(-4, 4, 7)
y = x**2 + rnd.random(x.shape)
p = np.polyfit(x, y, 2)
p
# array([ 0.96869003, -0.01157275, 0.69352514])
Linear algebra
NumPy can calculate matrix and vector products efficiently:
dot(),vdot(), …Eigenproblems:
linalg.eig(),linalg.eigvals(), …Linear systems and matrix inversion:
linalg.solve(),linalg.inv()
A = np.array(((2, 1), (1, 3)))
B = np.array(((-2, 4.2), (4.2, 6)))
C = np.dot(A, B)
b = np.array((1, 2))
np.linalg.solve(C, b) # solve C x = b
# array([ 0.04453441, 0.06882591])
Normally, NumPy utilises high performance libraries in linear algebra operations
Example: matrix multiplication C = A * B matrix dimension 1000
pure python: 522.30 s
naive C: 1.50 s
numpy.dot: 0.04 s
library call from C: 0.04 s
Pandas
Pandas is a Python package that provides high-performance and easy to use data structures and data analysis tools. Built on NumPy arrays, Pandas is particularly well suited to analyze tabular and time series data. Although NumPy could in principle deal with structured arrays (arrays with mixed data types), it is not efficient.
The core data structures of Pandas are Series and Dataframes.
A Pandas series is a one-dimensional NumPy array with an index which we could use to access the data
A dataframe consist of a table of values with labels for each row and column. A dataframe can combine multiple data types, such as numbers and text, but the data in each column is of the same type.
Each column of a dataframe is a series object - a dataframe is thus a collection of series.

Tidy vs untidy data
Let’s first look at the following two dataframes:
runners = pd.DataFrame([
{'Runner': 'Runner 1', 400: 64, 800: 128, 1200: 192, 1500: 240},
{'Runner': 'Runner 2', 400: 80, 800: 160, 1200: 240, 1500: 300},
{'Runner': 'Runner 3', 400: 96, 800: 192, 1200: 288, 1500: 360},
])
runners
# returns:
# Runner 400 800 1200 1500
# 0 Runner 1 64 128 192 240
# 1 Runner 2 80 160 240 300
# 2 Runner 3 96 192 288 360
# "melt" the data (opposite of "pivot")
runners = pd.melt(runners, id_vars="Runner",
value_vars=[400, 800, 1200, 1500],
var_name="distance",
value_name="time"
)
# returns:
# Runner distance time
# 0 Runner 1 400 64
# 1 Runner 2 400 80
# 2 Runner 3 400 96
# 3 Runner 1 800 128
# 4 Runner 2 800 160
# 5 Runner 3 800 192
# 6 Runner 1 1200 192
# 7 Runner 2 1200 240
# 8 Runner 3 1200 288
# 9 Runner 1 1500 240
# 10 Runner 2 1500 300
# 11 Runner 3 1500 360
Most tabular data is either in a tidy format or a untidy format (some people refer them as the long format or the wide format).
In untidy (wide) format, each row represents an observation consisting of multiple variables and each variable has its own column. This is intuitive and easy for us to understand and make comparisons across different variables, calculate statistics, etc.
In tidy (long) format , i.e. column-oriented format, each row represents only one variable of the observation, and can be considered “computer readable”.
When it comes to data analysis using Pandas, the tidy format is recommended:
Each column can be stored as a vector and this not only saves memory but also allows for vectorized calculations which are much faster.
It’s easier to filter, group, join and aggregate the data.
The name “tidy data” comes from Wickham’s paper (2014) which describes the ideas in great detail.
Data analysis workflow
Pandas is a powerful tool for many steps of a data analysis pipeline:
Downloading and reading in datasets
Initial exploration of data
Pre-processing and cleaning data
renaming, reshaping, reordering, type conversion, handling duplicate/missing/invalid data
Analysis
To explore some of the capabilities, we start with an example dataset containing the passenger list from the Titanic, which is often used in Kaggle competitions and data science tutorials. First step is to load Pandas and download the dataset into a dataframe:
import pandas as pd
url = "https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv"
# set the index to the "Name" column
titanic = pd.read_csv(url, index_col="Name")
Pandas also understands multiple other formats, for example read_excel(),
read_hdf(), read_json(), etc. (and corresponding methods to write to file:
to_csv(), to_excel(), to_hdf(), to_json(), …)
We can now view the dataframe to get an idea of what it contains and print some summary statistics of its numerical data:
# print the first 5 lines of the dataframe
titanic.head()
# print some information about the columns
titanic.info()
# print summary statistics for each column
titanic.describe()
Ok, so we have information on passenger names, survival (0 or 1), age, ticket fare, number of siblings/spouses, etc. With the summary statistics we see that the average age is 29.7 years, maximum ticket price is 512 USD, 38% of passengers survived, etc.
Unlike a NumPy array, a dataframe can combine multiple data types, such as
numbers and text, but the data in each column is of the same type. So we say a
column is of type int64 or of type object.
Indexing
Let’s inspect one column of the dataframe:
titanic["Age"]
titanic.Age # same as above
The columns have names. Here’s how to get them:
titanic.columns
However, the rows also have names! This is what Pandas calls the index:
titanic.index
We saw above how to select a single column, but there are many ways of selecting (and setting) single or multiple rows, columns and elements. We can refer to columns and rows either by number or by their name:
titanic.loc["Lam, Mr. Ali","Age"] # select single value by row and column
titanic.loc["Lam, Mr. Ali","Survived":"Age"] # slice the dataframe by row and column *names*
titanic.iloc[692,3:6] # same slice as above by row and column *numbers*
titanic.at["Lam, Mr. Ali","Age"] # select single value by row and column *name* (fast)
titanic.at["Lam, Mr. Ali","Age"] = 42 # set single value by row and column *name* (fast)
titanic.iat[692,4] # select same value by row and column *number* (fast)
titanic["somecolumns"] = "somevalue" # set a whole column
Dataframes also support boolean indexing:
titanic[titanic["Age"] > 70]
# ".str" creates a string object from a column
titanic[titanic.index.str.contains("Margaret")]
Missing/invalid data
What if your dataset has missing data? Pandas uses the value np.nan
to represent missing data, and by default does not include it in any computations.
We can find missing values, drop them from our dataframe, replace them
with any value we like or do forward or backward filling:
titanic.isna() # returns boolean mask of NaN values
titanic.dropna() # drop missing values
titanic.dropna(how="any") # or how="all"
titanic.dropna(subset=["Cabin"]) # only drop NaNs from one column
titanic.fillna(0) # replace NaNs with zero
titanic.fillna(method='ffill') # forward-fill NaNs
titanic.fillna(method='bfill') # backward-fill NaNs
Groupby
groupby() is a powerful method which splits a dataframe and aggregates data
in groups. To see what’s possible, let’s
test the old saying “Women and children first”. We start by creating a new
column Child to indicate whether a passenger was a child or not, based on
the existing Age column. For this example, let’s assume that you are a
child when you are younger than 12 years:
titanic["Child"] = titanic["Age"] < 12
Now we can test the saying by grouping the data on Sex and then creating
further sub-groups based on Child:
titanic.groupby(["Sex", "Child"])["Survived"].mean()
Here we chose to summarize the data by its mean, but many other common
statistical functions are available as dataframe methods, like
std(), min(), max(), cumsum(), median(), skew(),
var() etc.
The workflow of groupby() can be divided into three general steps:
Splitting: Partition the data into different groups based on some criterion.
Applying: Do some caclulation within each group. Different kinds of calulations might be aggregation, transformation, filtration.
Combining: Put the results back together into a single object.
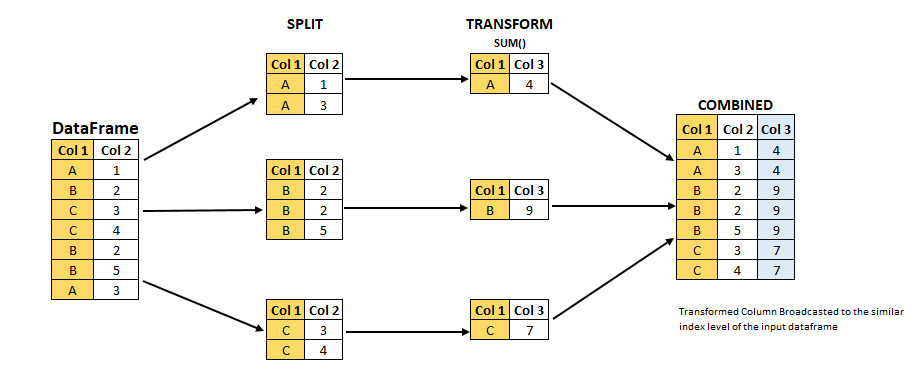
(Image source from lecture Earth and Environmental Data Science https://earth-env-data-science.github.io/intro.html)
For an overview of other data wrangling methods built into Pandas, have a look at Pandas (II).
Scipy
SciPy is a library that builds on top of NumPy. It contains a lot of interfaces to battle-tested numerical routines written in Fortran or C, as well as Python implementations of many common algorithms.
Briefly, SciPy contains functionality for
Special functions (Bessel, Gamma, etc.)
Numerical integration
Optimization
Interpolation
Fast Fourier Transform (FFT)
Signal processing
Linear algebra (more complete than in NumPy)
Sparse matrices
Statistics
More I/O routine, e.g. Matrix Market format for sparse matrices, MATLAB files (.mat), etc.
Many of these are not written specifically for SciPy, but use the best available open source C or Fortran libraries. Thus, you get the best of Python and the best of compiled languages.
Most functions are documented very well from a scientific standpoint: you aren’t just using some unknown function, but have a full scientific description and citation to the method and implementation.
Let us look more closely into one out of the countless useful functions available
in SciPy. curve_fit() is a non-linear least squares fitting function. NumPy
has least-squares fitting via the np.linalg.lstsq() function, but we need to
go to SciPy to find non-linear curve fitting.
This example fits a power-law to a vector:
import numpy as np
from scipy.optimize import curve_fit
def powerlaw(x, A, s):
return A * np.power(x, s)
# data
Y = np.array([9115, 8368, 7711, 5480, 3492, 3376, 2884, 2792, 2703, 2701])
X = np.arange(Y.shape[0]) + 1.0
# initial guess for variables
p0 = [100, -1]
# fit data
params, cov = curve_fit(f=powerlaw, xdata=X, ydata=Y, p0=p0, bounds=(-np.inf, np.inf))
print("A =", params[0], "+/-", cov[0,0]**0.5)
print("s =", params[1], "+/-", cov[1,1]**0.5)
# optionally plot
import matplotlib.pyplot as plt
plt.plot(X,Y)
plt.plot(X, powerlaw(X, params[0], params[1]))
plt.show()
In an exercise below, you will learn to perform an operation like curve fitting on all rows of a pandas dataframe in an effective manner.
Exercises
Working effectively with dataframes
Recall the curve_fit() method from SciPy discussed above, and imagine that we
want to fit powerlaws to every row in a large dataframe. How can this be done effectively?
First define the powerlaw() function and another function for fitting a row of numbers:
import numpy as np
import pandas as pd
from scipy.optimize import curve_fit
def powerlaw(x, A, s):
return A * np.power(x, s)
def fit_powerlaw(row):
X = np.arange(row.shape[0]) + 1.0
params, cov = curve_fit(f=powerlaw, xdata=X, ydata=row, p0=[100, -1], bounds=(-np.inf, np.inf))
return params[1]
Next load a dataset with multiple rows similar to the one used in the example above:
df = pd.read_csv("https://raw.githubusercontent.com/ENCCS/hpda-python/main/content/data/results.csv")
# print first few rows
df.head()
Now consider these four different ways of fitting a powerlaw to each row of the dataframe:
powers = []
for row_indx in range(df.shape[0]):
row = df.iloc[row_indx,1:]
p = fit_powerlaw(row)
powers.append(p)
powers = []
for row_indx,row in df.iterrows():
p = fit_powerlaw(row[1:])
powers.append(p)
powers = df.iloc[:,1:].apply(fit_powerlaw, axis=1)
# raw=True passes numpy ndarrays instead of series to fit_powerlaw
powers = df.iloc[:,1:].apply(fit_powerlaw, axis=1, raw=True)
Which one do you think is most efficient? You can measure the execution time
by adding %%timeit to the first line of a Jupyter code cell. More on timing
and profiling in a later episode.
Solution
The execution time drops as you go from the version in the left tab to the right tab:
%%timeit
powers = []
for row_indx in range(df.shape[0]):
row = df.iloc[row_indx,1:]
p = fit_powerlaw(row)
powers.append(p)
# 33.6 ms ± 682 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
powers = []
for row_indx,row in df.iterrows():
p = fit_powerlaw(row[1:])
powers.append(p)
# 28.7 ms ± 947 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
powers = df.iloc[:,1:].apply(fit_powerlaw, axis=1)
# 26.1 ms ± 1.19 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
powers = df.iloc[:,1:].apply(fit_powerlaw, axis=1, raw=True)
# 24 ms ± 1.27 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Further analysis of the Titanic passenger list dataset
Consider the titanic dataset. If you haven’t done so already, load it into a dataframe:
import pandas as pd
url = "https://raw.githubusercontent.com/pandas-dev/pandas/master/doc/data/titanic.csv"
titanic = pd.read_csv(url, index_col="Name")
Compute the mean age of the first 10 passengers by slicing and the
meanmethodUsing boolean indexing, compute the survival rate (mean of “Survived” values) among passengers over and under the average age.
Now investigate the family size of the passengers (i.e. the “SibSp” column):
What different family sizes exist in the passenger list? Hint: try the
unique()methodWhat are the names of the people in the largest family group?
(Advanced) Create histograms showing the distribution of family sizes for passengers split by the fare, i.e. one group of high-fare passengers (where the fare is above average) and one for low-fare passengers (Hint: instead of an existing column name, you can give a lambda function as a parameter to
histto compute a value on the fly. For examplelambda x: "Poor" if titanic["Fare"].loc[x] < titanic["Fare"].mean() else "Rich").
Solution
Mean age of the first 10 passengers:
titanic.iloc[:10,:]["Age"].mean()ortitanic.iloc[:10,4].mean()ortitanic.loc[:"Nasser, Mrs. Nicholas (Adele Achem)", "Age"].mean().Survival rate among passengers over and under average age:
titanic[titanic["Age"] > titanic["Age"].mean()]["Survived"].mean()andtitanic[titanic["Age"] < titanic["Age"].mean()]["Survived"].mean().Existing family sizes:
titanic["SibSp"].unique()Names of members of largest family(ies):
titanic[titanic["SibSp"] == 8].indextitanic.hist("SibSp", lambda x: "Poor" if titanic["Fare"].loc[x] < titanic["Fare"].mean() else "Rich", rwidth=0.9)
See also
NumPy documentation
Pandas getting started guide
Pandas documentation containing a user guide, API reference and contribution guide.
Pandas cheatsheet
Pandas cookbook.
Scipy documentation
Keypoints
NumPy provides a static array data structure, fast mathematical operations for arrays and tools for linear algebra and random numbers
Pandas dataframes are a good data structure for tabular data
Dataframes allow both simple and advanced analysis in very compact form
SciPy contains a lot of interfaces to battle-tested numerical routines